ChatGPT’s extensive language capabilities have effectively drawn in the general population. Soon after its debut, the AI chatbot excels in a wide range of language tasks, such as writing lyrics, poetry, essays, and codes. ChatGPT, which is based on the Generative Pre-training Transformer (GPT) architecture, is an example of what large language models (LLMs) can do, especially when they are modified for usage in business applications. One of the examples of domain-specific LLMs, known as LegalBERT (Legal LLM) achieved 25% better accuracy on legal-specific tasks like legal text classification compared to generic LLMs and fine-tuned on 12 GB of legal text data sourced from court decisions, contracts, and legislation.
Despite their widespread use, basic models like GPT, LlaMa, and Falcon are only appropriate for jobs that require additional fine-tuning. Foundational models lack the domain-specific information necessary to be useful in the majority of industrial or corporate applications, despite their exceptional performance in a wider context.
In this blog, we’ll understand the basics and how to create a domain-specific LLM along with their use cases and applications in more depth.
What is a Domain-Specific LLM?
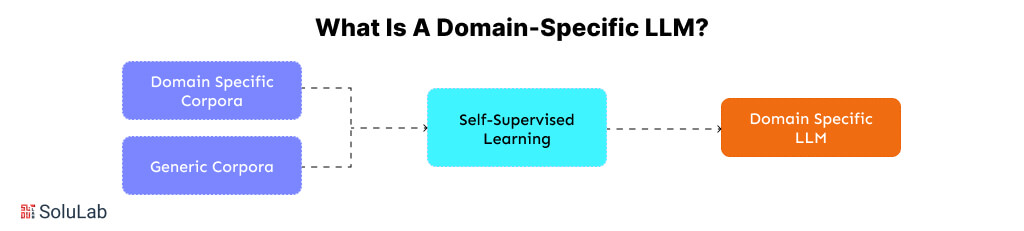
A domain-specific LLM is a generic model that has been trained or optimized to carry out specific activities that are governed by corporate policies.
The shortcomings of generic LLMs in specialized disciplines are intended to be addressed by domain-specific large language models. A domain-specific LLM concentrates on a specific field, in contrast to its generic counterparts, which are trained on a broad range of text sources to gain comprehensive knowledge applicable across various domains.
Specialized fields having their own jargon, procedures, and communication standards, such as law, medicine, IT, finance, or insurance, may fall under this category. Building upon this basis, domain-specific LLMs frequently start out as small language models that are then enhanced and improved by fine-tuning LLM approaches.
Fine-tuning entails modifying the model using a condensed dataset that is abundant in case studies, scenarios, and specialized language relevant to the subject in question. This fine-tuning process, often referred to as Parameter-Efficient Fine-Tuning (PEFT), focuses on adapting the model effectively by leveraging task-specific data while minimizing the need for extensive computational resources. The objective is to fine-tune LLM to review requests that match certain guidelines, equipping it with the skills necessary to comprehend and produce literature that adheres to the complex demands of the area and professional norms.
In the targeted industry, this customized methodology guarantees that Domain-specific LLMs provide unmatched accuracy and relevance in their outputs, greatly improving research skills, decision-making, and customer interactions. These models go beyond the abilities of generic LLMs by focusing on the unique requirements and complexity of each domain, giving businesses a competitive edge through sophisticated and industry-specific AI solutions. Using a customized model trained for specific use cases improves these solutions’ accuracy and applicability even further.
The Importance of Domain-Specific LLMs in Data-Driven Fields
The fundamental difference between domain-specific LLMs and general-purpose models lies in their training and use. Custom-trained language models are developed using datasets that are densely focused on specific fields, adapting to the distinct needs and characteristics of these domains. This targeted training approach allows them to achieve a deeper understanding and mastery of specialized subjects, making them essential for tasks that demand expert-level knowledge.
For example, in the healthcare sector, custom LLMs excel at processing and generating content related to medical terminologies, procedures, and patient care. These models significantly outperform generic LLMs when applied to medical contexts, providing a higher level of accuracy and relevance.
The process of training custom LLMs not only improves their efficiency in specialized tasks but also ensures more precise and contextually appropriate outputs. This underscores the value of rigorous evaluation to measure the performance and reliability of such models. As a result, these domain-specific custom LLMs have become indispensable for professionals in fields where precision and expertise are critical.
Why Build a Domain-Specific LLM?
General-purpose LLMs are celebrated for their scalability and conversational capabilities. These models allow anyone to interact with them and receive human-like responses, a remarkable advancement that seemed unimaginable to the public just a few years ago but is now a reality.
However, foundational models have their limitations despite their impressive natural language processing capabilities. It didn’t take long for users to realize that these models, such as ChatGPT, can hallucinate and produce inaccurate information when prompted. For instance, a lawyer who relied on the chatbot for research ended up presenting fabricated cases to the court.
The truth is that foundational models lack the ability to comprehend specific contexts beyond the vast datasets they were trained on. If a language model hasn’t been trained with legal corpora or doesn’t include safeguards to identify fake outputs, it can create fictional scenarios or misinterpret the nuances of legal cases.
As we admire how naturally large language model operations (LLMOps) can interact, it’s crucial to remember their limitations. At their core, domain-specific language models are powered by neural networks designed to predict linguistic patterns. They cannot discern truths in the way humans do or link textual concepts to objects or events in the real world.
Another limitation of general LLMs is their difficulty with processing lengthy contexts. For example, GPT-4 can handle up to 4K tokens, though a version supporting 32K tokens is in development. Without a sufficiently large context window, an LLM may struggle to produce coherent and relevant outputs.
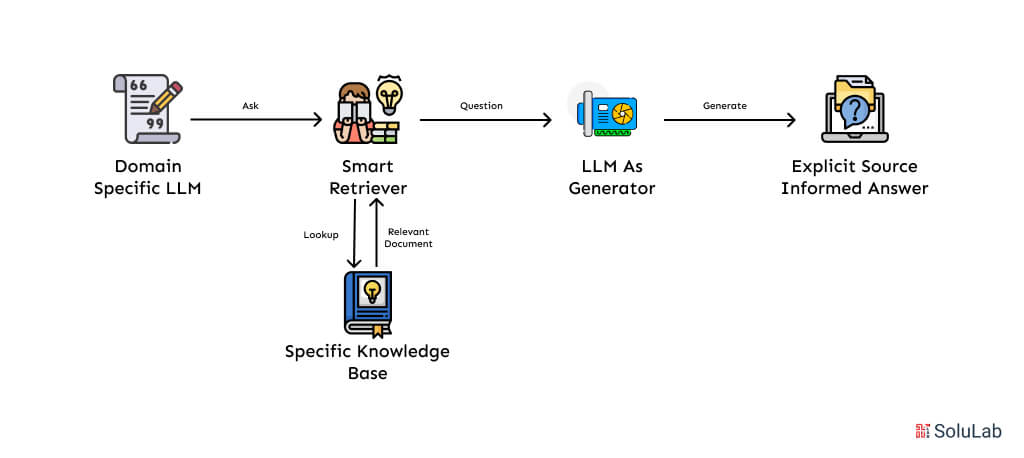
This is where the need to fine-tune LLM for domain-specific needs arises. Customizing a model with specialized knowledge enables it to operate more accurately within its intended context. By building a domain-specific LLM, organizations can ensure their models are tailored to their specific requirements. For example, a fine-tuned, domain-specific LLM combined with semantic search can deliver precise and contextually relevant results in a conversational manner, making it a powerful tool for specialized applications.
How to Create a Domain-Specific LLM?
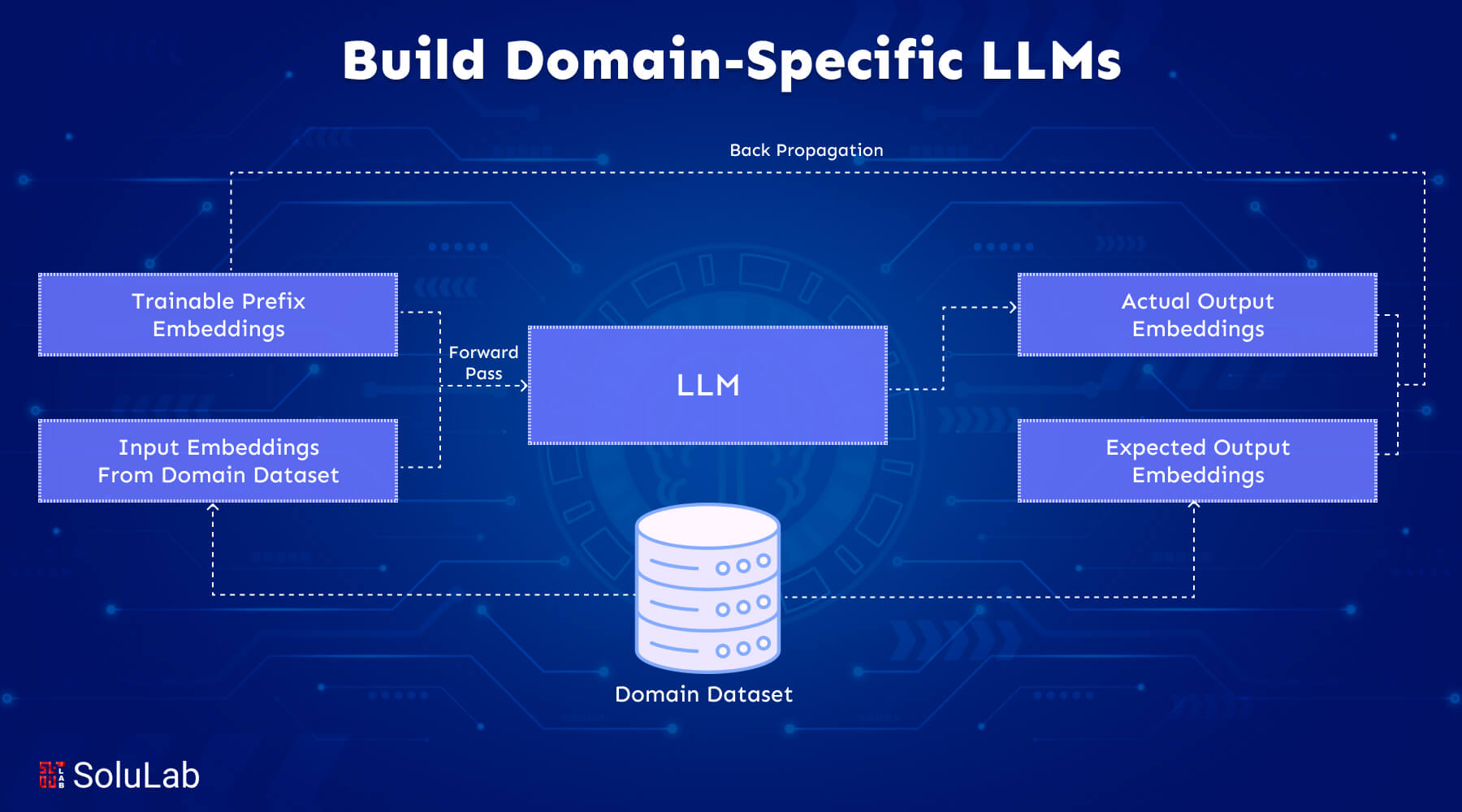
Developing a domain-specific large language model (LLM) requires a well-structured methodology. The process starts with broad training on diverse data and transitions to fine-tuning with specialized datasets. This ensures the models are both broadly competent and optimized for AI for domain-specific tasks.
Base Model Training
-
General Training Data
Initially, LLMs are trained on extensive datasets drawn from various sources, such as web pages, books, and articles. This phase equips the models with a broad understanding of language, enabling them to perform tasks like translation, summarization, and question-answering.
-
Specialized Training Data
To make the models applicable to specific industries, they are fine-tuned using domain-specific datasets. This step involves training the model with field-specific materials, such as healthcare records for medical applications, legal documents for the legal sector, or financial reports for finance.
How to Fine-Tune an LLM?
The fine-tuning phase customizes a broadly trained base model to excel in specialized tasks. It ensures the model retains its general linguistic capabilities while enhancing its performance in domain-specific contexts. Depending on the application, various techniques can be employed to fine-tune the model effectively:
| Technique | Description | Example |
| Task-Specific Fine-Tuning | Updating all parameters of the pre-trained model using a dataset tailored to a specific task. | Fine-tuning BERT for sentiment analysis on movie reviews. |
| Feature-Based Approach | Keeping the pre-trained model’s parameters fixed and adding task-specific layers. | Adding a classifier layer to a pre-trained BERT model for text classification. |
| Transfer Learning Techniques | Adopting a two-step process: intermediate task fine-tuning before final task-specific training. | Fine-tuning on a general news dataset before a smaller domain-specific news corpus. |
| Domain-Adaptive Pre-Training | Additional pre-training on domain-specific unlabeled data before task-specific fine-tuning. | Pre-training BERT with medical texts before fine-tuning for medical entity recognition tasks. |
| Adversarial Training | Training the model with adversarial examples to improve robustness and generalization. | Fine-tuning with perturbed inputs to increase resilience against input variations. |
| Multi-Task Learning | Training on multiple tasks simultaneously, sharing parameters across tasks for improved results. | Combining training for text classification and named entity recognition (NER). |
| Meta-Learning | Teaching the model to adapt quickly to new tasks with limited data. | Using MAML for rapid fine-tuning with a small number of training examples. |
| Distillation and Pruning | Compressing a larger model into a smaller one and removing redundant weights to enhance efficiency. | Using DistilBERT as a distilled version of BERT for faster and smaller-scale deployments. |
| Parameter-Efficient Fine-Tuning | Adding small, trainable modules or using low-rank matrices to optimize training processes. | Inserting adapters in BERT or using LoRA for domain adaptation. |
| Prompt-Based Fine-Tuning | Incorporating task-specific prompts in the input text to guide fine-tuning. | Adding prompts like “Question: [text]” for question-answering tasks. |
| Self-Supervised Fine-Tuning | Using self-supervised objectives alongside task-specific ones. | Using masked language modeling or next sentence prediction during task fine-tuning. |
Validation and Testing
To ensure the accuracy and reliability of domain-specific LLMs for practical applications, comprehensive validation and testing of custom-trained language models are essential:
-
Performance Validation
Validate the model’s outputs using benchmarks specific to the domain, ensuring they meet the necessary standards of accuracy and reliability.
-
Continuous Feedback and Iteration
Gather real-world feedback and update the model regularly to improve its effectiveness and accuracy over time. This iterative process ensures the model remains relevant to AI for domain-specific tasks.
Benefits of Fine-Tuned LLMs
Fine-tuning a large language model (LLM) offers numerous advantages by adapting a pre-trained base model to address specific tasks, industries, or user needs. This process enables organizations to leverage the full potential of LLMs with enhanced precision, efficiency, and relevance. Below are the key benefits of fine-tuned LLMs:
1. Task-Specific Performance
Fine-tuned LLMs are optimized to excel in specific tasks, such as legal document analysis, sentiment detection, or customer support. By training on task-relevant datasets, these models outperform generic LLMs in producing accurate and reliable results tailored to a given use case.
2. Higher Accuracy and Contextual Understanding
By focusing on domain-specific data, fine-tuned LLMs achieve greater contextual understanding and produce highly accurate outputs. For example, a fine-tuned model in the healthcare domain can interpret medical terminology more effectively, ensuring precision in diagnoses or treatment recommendations.
3. Reduced Computational Costs
Fine-tuning builds upon a pre-trained model rather than training from scratch, significantly reducing computational costs and development time. This makes it a more efficient way to create customized solutions without requiring massive datasets or resources.

4. Customization and Flexibility
Fine-tuned LLMs are adaptable to the specific needs of businesses or industries. Organizations can design models to address unique challenges, ensuring the outputs align with their operational goals and priorities.
5. Improved Reliability and Reduced Hallucinations
Generic models can often produce fabricated or irrelevant information. Fine-tuning minimizes such risks by training the model on highly curated and relevant datasets. This process ensures that the model generates more consistent and trustworthy outputs.
6. Enhanced User Experience
Fine-tuned models deliver more personalized and contextually appropriate responses, leading to improved user satisfaction. For instance, a customer service chatbot powered by a fine-tuned LLM can provide faster and more accurate answers to industry-specific queries.
Challenges in Building Domain-Specific LLMs
Creating robust domain-specific LLMs requires overcoming several challenges, such as ensuring data quality, managing scalability, and integrating interdisciplinary knowledge.
| Challenge | Description | Solution |
| Data Quality and Availability | High-quality annotated datasets are often scarce, particularly in regulated fields like healthcare. | Collaborate with industry partners to access data, use data augmentation, and generate synthetic datasets. |
| Scalability and Cost Management | Training and fine-tuning LLMs require significant computational resources and expertise. | Use cloud-based AI platforms and transfer learning to reduce costs and simplify scaling. |
| Interdisciplinary Integration | Domain-specific models struggle with queries that span multiple fields. | Develop hybrid models or multi-domain systems to combine expertise across various fields. |
By addressing these challenges and adopting structured methodologies, organizations can effectively fine-tune an LLM for domain-specific needs, ensuring it meets their unique requirements with precision and efficiency.
Examples of Domain-Specific LLMs
Recognizing the limitations of general-purpose language models, industry leaders took the initiative to develop domain-specific language models customized to their respective fields. Here are some notable examples of domain-specific LLMs:
-
BloombergGPT
BloombergGPT is a causal language model built using a decoder-only architecture. With 50 billion parameters, it was trained from the ground up using decades of financial data. This AI for domain-specific tasks excels in financial applications, outperforming other models significantly on financial-specific tasks while matching or exceeding their performance on general language tasks.
-
Med-PaLM 2
Med-PaLM 2 is a specialized model developed by Google and trained on meticulously curated medical datasets. This domain-specific LLMs example demonstrates exceptional accuracy in answering medical questions, sometimes performing at the level of medical professionals. On the MedQA dataset, which includes questions from the US Medical Licensing Examination, Med-PaLM 2 achieved an impressive score of 86.5%.
-
ClimateBERT
ClimateBERT is a transformer-based model trained on millions of climate-related datasets. Through fine-tuning, it empowers organizations to perform fact-checking and other language tasks with greater precision on environmental data. Compared to general-purpose models, ClimateBERT reduces errors in climate-related tasks by up to 35.7%.
-
KAI-GPT
KAI-GPT, developed by Kasisto, is a large language model designed to deliver conversational AI solutions in the banking sector. It ensures safe, transparent, and accurate applications of generative AI in customer service, making it a reliable option for financial institutions seeking domain-specific language models.
-
ChatLAW
ChatLAW is an open-source language model trained specifically with datasets from the Chinese legal domain. The model features several enhancements, including a unique method to reduce hallucinations and improve inference accuracy, making it highly effective for legal applications in China.
-
FinGPT
FinGPT is a lightweight model pre-trained with financial datasets, offering a cost-effective alternative to BloombergGPT. This model incorporates reinforcement learning from human feedback, allowing for further personalization. It performs exceptionally well on financial sentiment analysis datasets, solidifying its position as one of the top examples of domain-specific LLMs in the financial sector.
These domain-specific LLMs examples demonstrate how tailored models are pushing the boundaries of AI for domain-specific tasks, enabling precise and effective solutions across industries.
Use Cases for Domain-Specific LLMs
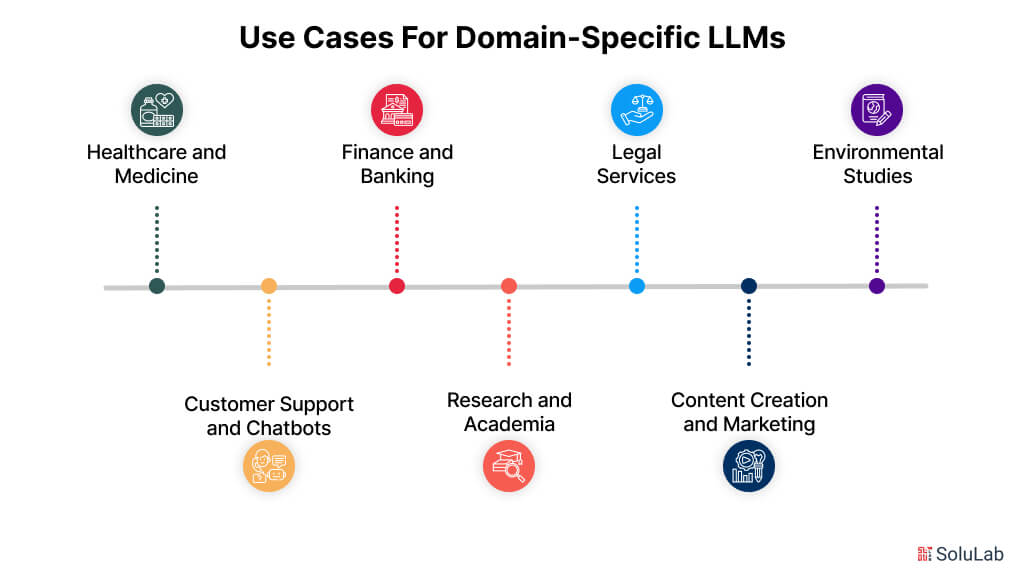
Domain-specific large language models (LLMs) are transforming industries by offering tailored solutions that general-purpose models struggle to provide. These models are designed to excel in tasks requiring specialized knowledge, making them indispensable in several fields. Here are some prominent LLMs use cases:
1. Healthcare and Medicine
Domain-specific LLMs like Med-PaLM 2 are revolutionizing medical practice. They assist healthcare professionals by accurately interpreting medical records, answering complex medical queries, and even supporting diagnostic decision-making. These models are also being used in telemedicine to provide reliable and precise consultations, reducing the workload on practitioners.
2. Finance and Banking
In the financial sector, models like BloombergGPT and FinGPT streamline data analysis, sentiment detection, and market forecasting. Financial institutions are leveraging these LLMs to enhance customer service, automate compliance checks, and analyze market trends more efficiently, providing a competitive edge in decision-making.
3. Legal Services
Legal professionals benefit from domain-specific models such as ChatLAW, which are trained on vast legal corpora to assist in drafting contracts, summarizing case laws, and identifying potential legal risks. These models also help in regulatory compliance by cross-referencing laws and regulations specific to a jurisdiction.
4. Environmental Studies
Climate-focused models like ClimateBERT empower researchers and organizations to analyze climate data, verify facts, and generate reports on environmental issues. By minimizing errors in climate-related tasks, these models enable more accurate decision-making for sustainability initiatives and policy development.
5. Customer Support and Chatbots
Custom models like KAI-GPT are transforming customer support in industries such as banking, retail, and telecommunications. These LLMs deliver industry-specific conversational AI solutions that understand domain-specific terminology, ensuring accurate responses and a better customer experience.
6. Research and Academia
Researchers across domains use tailored LLMs to extract insights from vast datasets, automate literature reviews, and assist in drafting research papers. These models accelerate the research process while maintaining high levels of precision in domain-specific outputs.
7. Content Creation and Marketing
Companies are utilizing domain-specific LLMs to generate targeted content that resonates with specific audiences. For example, an LLM trained in fashion or technology can create blog posts, social media content, or product descriptions that align with the industry’s language and trends.
By focusing on the unique needs of specific fields, domain-specific LLMs are driving innovation and enabling organizations to solve complex problems with unparalleled accuracy and efficiency.
Benefits of Domain-Specific LLMs
Domain-specific large language models (LLMs) are redefining how industries tackle specialized tasks. By tailoring language models to specific fields, businesses, and professionals gain significant advantages over using general-purpose models. Here are the key benefits:
1. Improved Accuracy and Relevance
Domain-specific LLMs are trained on curated datasets unique to their respective industries. This specialization enables them to provide highly accurate and contextually relevant outputs, reducing the risk of errors that general models might produce in specialized tasks, such as medical diagnostics or legal document analysis.
2. Enhanced Efficiency
Tailored models streamline complex workflows by automating repetitive and knowledge-intensive tasks. Whether summarizing financial reports, extracting legal clauses, or analyzing climate data, these models save time and resources, allowing experts to focus on strategic decision-making.
3. Better Decision Support
By delivering outputs that align with domain-specific requirements, these LLMs support better decision-making. For instance, financial LLMs can provide precise market insights, while healthcare models can aid in diagnosis and treatment planning, offering valuable assistance to professionals.
4. Reduced Hallucinations
Unlike general-purpose models that often generate irrelevant or fabricated information, domain-specific LLMs are less prone to hallucinations. With focused training data and domain-specific safeguards, they deliver more reliable results, especially in critical applications such as law, finance, or healthcare.
5. Customization for Unique Needs
Domain-specific LLMs allow organizations to tailor models to their exact requirements. Customization enables businesses to address niche challenges, ensuring the model aligns with their operational goals and industry standards.
6. Increased User Trust and Adoption
When outputs are accurate and relevant, users develop greater trust in the technology. This trust fosters higher adoption rates of domain-specific solutions, as users feel confident in relying on the model for critical tasks and insights.
7. Cost-Effective Solutions for Specialized Tasks
By focusing only on relevant datasets and use cases, domain-specific LLMs reduce computational costs compared to deploying overly generalized models. This makes them a cost-effective choice for businesses seeking specialized AI-driven solutions.
Domain-specific LLMs not only address the limitations of generic models but also open up new possibilities for industry-specific innovation, making them indispensable in fields where precision and expertise are paramount.
Best Practices for Training an LLM
Training and fine-tuning large language models (LLMs) is a complex process that involves addressing both ethical and technical challenges. Teams must manage computational costs, leverage domain expertise, and ensure the model achieves the desired accuracy. Mistakes made during the training process can propagate throughout the entire pipeline, impacting the final application. These best practices will help guide your efforts when training a domain-specific LLM or custom LLMs for specialized applications.
-
Start Small
Avoid being overly ambitious when developing a model. Instead of targeting multiple use cases, focus on training the LLM for a specific task. For example, train a custom LLM to enhance customer service as a product-aware chatbot. Deploy the tailored model and only scale further if it proves successful in its initial application.
-
Understand Scaling Laws
Scaling laws in deep learning examine the relationship between compute power, dataset size, and the number of parameters in a language model. OpenAI initiated this research in 2020 to predict a model’s performance before training, recognizing that building a large LLM, such as GPT, requires substantial time and cost.
Key insights from scaling laws include:
- Larger models outperform smaller ones when trained on the same dataset and reach desired performance levels faster.
- Expanding a model’s architecture has a greater impact on performance than simply increasing the dataset size, provided sufficient compute resources are available.
However, DeepMind’s 2022 research challenged these findings, showing that both model size and dataset size are equally important in enhancing the performance of AI for domain-specific tasks.
-
Prioritize Data Quality
High-quality, domain-specific training data is essential for creating an effective domain-specific LLM. Training data must represent the diversity of real-world scenarios to prevent bias and ensure generalizability. For instance, financial institutions should train credit scoring models with datasets that reflect the demographics of their customer base to avoid deploying biased systems that may misjudge credit applications.
Whether building a model from scratch or fine-tuning an existing one, ML teams should ensure datasets are free of noise, inconsistencies, and duplicates. Proper data preparation is critical to achieving fairness and accuracy in the model’s predictions.
-
Enforce Data Security and Privacy
The massive datasets used to train or fine-tune custom LLMs present significant privacy risks. Threats to the machine learning pipeline, such as data breaches, could harm an organization’s reputation and compromise user privacy.
Organizations must adopt stringent data security measures, such as encrypting sensitive data during storage and transmission. These practices are also essential for compliance with industry regulations like HIPAA and PCI-DSS.
-
Monitor and Evaluate Model Performance
Once an LLM is deployed, ongoing monitoring is essential to ensure it meets real-world expectations and adheres to established benchmarks. If the model underperforms or exhibits issues such as bias or underfitting, it should be refined with additional training data, adjusted hyperparameters, or updated training processes.
Continuous evaluation allows AI for domain-specific tasks to remain effective and relevant in dynamic environments, ensuring it adapts to changing requirements and real-world circumstances.
By following these best practices, teams can successfully train and fine-tune domain-specific LLMs, ensuring their models are accurate, reliable, and aligned with the unique needs of their application.

The Bottom Line
Domain-specific LLMs are more suited to knowledge-specific activities. Leading artificial intelligence vendors are aware of the limits of general language models in particular applications. They created domain-specific models, such as BloombergGPT, Med-PaLM 2, and ClimateBERT, to fulfill specialized jobs. A comparison of LLM performance shows that domain-specific models excel at uncovering financial opportunities, increasing operational efficiency, and upgrading the consumer experience. The insights gained from several industry-specific LLMs highlight the significance of customized training and fine-tuning. Organizations that use high-quality, domain-specific data may dramatically improve the capabilities and efficiency of their AI models.
SoluLab, a leading LLM development company, recently launched an AI-powered chatbot for travel recommendations in partnership with Digital Quest. The chatbot is designed to provide seamless communication and personalized travel suggestions, enhancing the experience for travelers.
At SoluLab, we specialize in creating AI solutions customized to your business needs. From building intelligent chatbots to streamlining customer interactions and improving operational efficiency, our team is ready to help bring your vision to life. Contact us today to get started!
FAQs
1. What is a domain-specific LLM, and why is it important?
A domain-specific LLM (Large Language Model) is a language model fine-tuned on specialized data relevant to a particular industry or niche. It improves accuracy, relevance, and performance for tasks within that domain, making it ideal for use cases like healthcare, finance, or legal applications.
2. How do you fine-tune a pre-trained LLM for a specific domain?
To fine-tune a pre-trained LLM, gather a high-quality, domain-specific dataset and use transfer learning techniques. This involves training the model on the specialized data while keeping the pre-trained knowledge as a base, thus adapting it to the target domain.
3. What types of data are required to train domain-specific LLMs?
Training domain-specific LLMs requires clean, high-quality, and labeled domain-specific datasets. Examples include research papers, technical documents, industry reports, FAQs, or other structured and unstructured textual content relevant to the domain.
4. How do you evaluate the performance of a domain-specific LLM?
Performance can be evaluated using domain-specific benchmarks, accuracy metrics (e.g., BLEU, ROUGE), and real-world testing for tasks like classification, summarization, or question-answering. Human evaluation within the domain also ensures relevance and precision.
5. What are the benefits of building domain-specific LLMs instead of using general-purpose LLMs?
Domain-specific LLMs offer higher accuracy, relevance, and efficiency for specialized tasks. Unlike general-purpose LLMs, they understand domain-specific terminology, context, and nuances, delivering better results for niche use cases.


