Generative Adversarial Networks (GANs) are among the most interesting developments in artificial intelligence (AI) and deep learning. GANs, invented by Ian Goodfellow and his colleagues in 2014, have transformed how we handle machine learning, particularly in picture and video production, text-to-image synthesis, and others.
Generative Adversarial Networks (GANs), a key aspect of generative adversarial network AI, focus on creation, such as producing a portrait or composing a symphony entirely from scratch, making them more challenging compared to other areas of deep learning. Identifying a Van Gogh painting is significantly simpler than having computers or individuals recreate one.
Nevertheless, generative adversarial networks advance our understanding of intelligence.
The research community has recognized GANs globally for their extensive potential. They have been instrumental in addressing data generation and data annotation challenges across various domains, including image, audio, video, and text.
This guide gives a complete introduction to GANs, describing what they are, how they function, how they are used, and the issues they provide.
What is a Generative Adversarial Network?
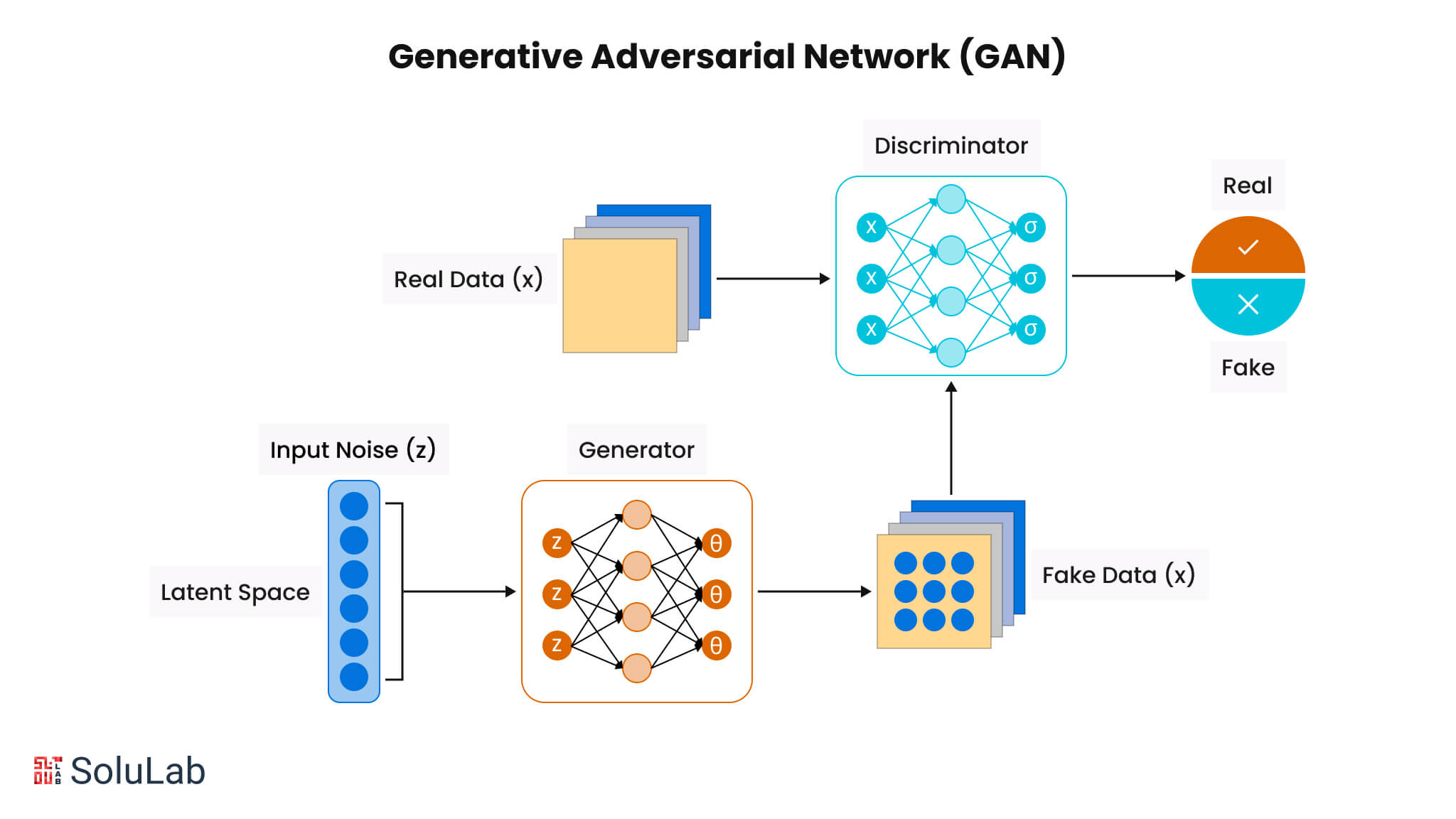
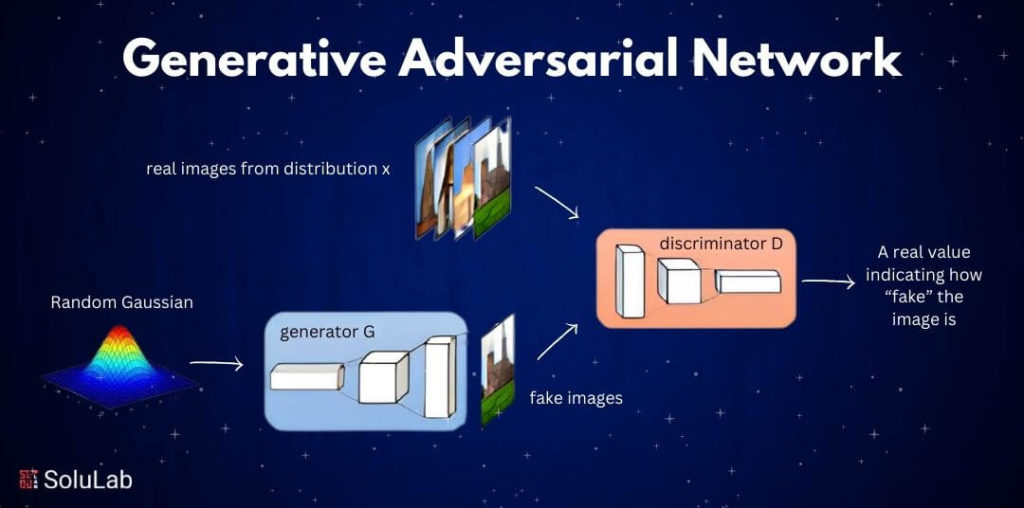
A generative adversarial network, or GAN, is a framework for deep neural networks that can learn from training data and generate new data with similar characteristics to the training data. For instance, generative networks trained on photographs of human faces can create realistic-looking faces that are completely fictitious.
The generative adversarial networks definition consists of two neural networks, the generator and the discriminator, which compete against one another. The generator is designed to produce fake data, while the discriminator is trained to differentiate the generator’s fake data from actual examples.
Intuitively, the generator transforms random noise through a model to create a sample, and the discriminator determines whether the sample is real or not.
The image below illustrates how GANs are trained. There are two fundamental components in GANs:
- Generator: The generator receives random noise as input and generates a data sample, ideally within the latent space of the input dataset. Throughout the training process, it aims to replicate the distribution of the input dataset.
- Discriminator: The discriminator network acts as a binary classifier that determines whether the sample is real or fake. The input to the discriminator can come either from an input dataset or the generator, and its role is to classify whether the sample is real or fake.
This explanation defines generative adversarial networks and provides insights into generative adversarial networks images.
Working of Generative Adversarial Network
So, GANs consist of two networks that must be trained separately. The framework of GANs is quite simple when both models are multilayer perceptrons. Let’s delve into how GANs operate.
Initially, a random normal distribution is inputted into the generator, which then produces a random distribution since it lacks a reference point. Simultaneously, an actual sample, or ground truth, is provided to the discriminator. The discriminator learns the distribution of the real sample. When the generated sample from the generator is presented to the discriminator, it evaluates the distribution. If the generated sample’s distribution closely resembles the original sample, the discriminator outputs a value near ‘1’, indicating it is real. Conversely, if the distributions differ significantly, the discriminator outputs a value near ‘0’, signifying it is fake.
How does the generator evolve to create samples that resemble the actual data?
To understand the generator’s evolution, we must look at how the discriminator assesses whether a generated sample is real or fake. The key lies in the loss function, which measures the distance between the generated data distribution and that of the real data. Each network has its own loss function: the generator seeks to minimize its loss, while the discriminator aims to maximize it.
The generator is indirectly linked to the loss through the discriminator. The discriminator outputs whether a sample is fake or real. If the output is ‘0’ (fake), the generator receives a penalty for producing a sample classified as fake.
After calculating the loss, the generator’s weights are updated using backpropagation through the discriminator network. This is crucial because the generator’s parameters significantly depend on the discriminator’s feedback, allowing the generator to refine its output to produce samples that appear more ‘real’.
1. Training Process
For each training step, we begin with the discriminator loop, which we want to repeat several times before transitioning to the generator loop.
Discriminator Loop:
- Set a loop kkk where k>1k > 1k>1 to ensure that the discriminator becomes a reliable estimator of the original data distribution pdp_dpd.
- Sample mmm noise data from a normal distribution z1,z2,z3,…,zn{z_1, z_2, z_3, \ldots, z_n}z1,z2,z3,…,zn and transform them through the generator.
- Sample mmm real data from a normal distribution x1,x2,x3,…,xn{x_1, x_2, x_3, \ldots, x_n}x1,x2,x3,…,xn.
- It’s important to note that fake samples are labeled as zero and real samples as one.
- Use the loss function to calculate the loss using these labels.
- Compute the gradient of the loss function with respect to the discriminator parameters and update the discriminator’s weights. We use gradient ascent for this update because our goal is to maximize the loss.
This completes the discriminator loop.
Generator Loop:
The generator loop follows a similar approach:
- Sample mmm noise data from a normal distribution z1,z2,z3,…,zn{z_1, z_2, z_3, \ldots, z_n}z1,z2,z3,…,zn and transform them through the generator to produce fake samples.
- Since we focus solely on updating the generator, we compute the gradient of the loss function concerning the generator, ultimately setting the derivatives to zero.
- The cost function in the generator loop doesn’t include the real sample, simplifying it to the generator’s loss.
Using this equation, we can update the generator’s weights through gradient descent.
It’s fascinating that the generator evolves while treating the discriminator as a constant. The discriminator acts as a guide, helping the generator learn and improve!

2. Generative Adversarial Networks Loss Functions
Two main loss functions dominate GANs:
- Min-Max Loss
- Wasserstein Loss
Minimax Loss:
The minimax approach focuses on maximizing one player’s error while minimizing the other’s. This concept was introduced in the 2014 paper by Ian Goodfellow et al. titled “Generative Adversarial Networks.”
Minimax loss stems from game theory, where players compete against each other. To succeed, a player must maximize their own chances of winning while minimizing those of their opponent by predicting the best moves the opponent can make.
In this context, the discriminator is the player aiming to maximize its probability of success by accurately classifying fake images generated by the generator. Initially, it learns from real images, outputting D(x)=1D(x) = 1D(x)=1, and then from fake images, outputting D(G(x))=0D(G(x)) = 0D(G(x))=0.
The goal is to maximize the difference between 1−D(G(x))1 – D(G(x))1−D(G(x)). A larger difference indicates that the discriminator is effectively classifying real and fake images. Meanwhile, the generator strives to minimize this probability by working to make D(G(x))D(G(x))D(G(x)) closer to 1, ultimately aiming to lower the loss to near zero.
This iterative process continues until one player assists the other in evolving or until the training iteration ends.
Wasserstein Loss:
The Wasserstein loss function was developed for a new type of GAN called the Wasserstein GAN (WGAN). In this setup, the discriminator doesn’t classify outputs as fake or real; instead, it outputs a continuous number for each generated sample. Real samples yield larger numbers, while fake samples produce smaller ones.
In Wasserstein generative adversarial nets, the discriminator, referred to as a “critic,” uses the following loss functions:
- Critic Loss: C(x)−C(G(z))C(x) – C(G(z))C(x)−C(G(z))
The critic attempts to maximize this function, which mirrors the minimax function discussed earlier. It seeks to maximize the difference between real instances and fake instances.
- Generator Loss: C(G(z))C(G(z))C(G(z))
The generator aims to maximize this output, which means it works to increase the critic’s score for its fake instances.
Why Were GANs Developed?
Traditional machine learning algorithms and neural networks have a significant vulnerability: they can easily be misled into misclassifying data when even a minimal amount of noise is introduced. By adding slight distortions or random noise to the data, the chances of neural networks making incorrect classifications, especially with images, increase dramatically. This limitation exposed a need for more advanced models capable of handling such distortions and learning to generate new data patterns rather than simply recognizing them.
This challenge sparked the development of Generative Adversarial Networks (GANs). The core idea behind GANs is to enable neural networks to visualize and create new patterns that mimic the original training data, making them a crucial tool in generative AI for data analysis and modeling. Instead of just classifying or recognizing images, GANs can generate entirely new samples that are remarkably similar to the real data. The introduction of GANs allowed for the creation of synthetic data that could effectively fool even well-trained neural networks, making them an essential tool in fields like image, audio, and video generation.
As GANs evolved, specific frameworks like the PyTorch generative adversarial network emerged, offering a powerful platform for implementing GANs. PyTorch provides flexibility and ease of use, making it popular among researchers and developers for creating and training GANs in various domains. Its dynamic computational graph allows for more intuitive development and testing of models, speeding up the process of generating high-quality synthetic data.
Another significant advancement is the development of the 3D generative adversarial network, which extends GAN capabilities to three-dimensional data. This innovation has opened up new possibilities in industries such as gaming, medical imaging, and virtual reality, where generating realistic 3D models and environments is crucial. With 3D GANs, systems can now generate lifelike 3D objects and scenes that closely resemble real-world counterparts, enhancing applications in simulation, design, and entertainment.
What are the Types of GANs?
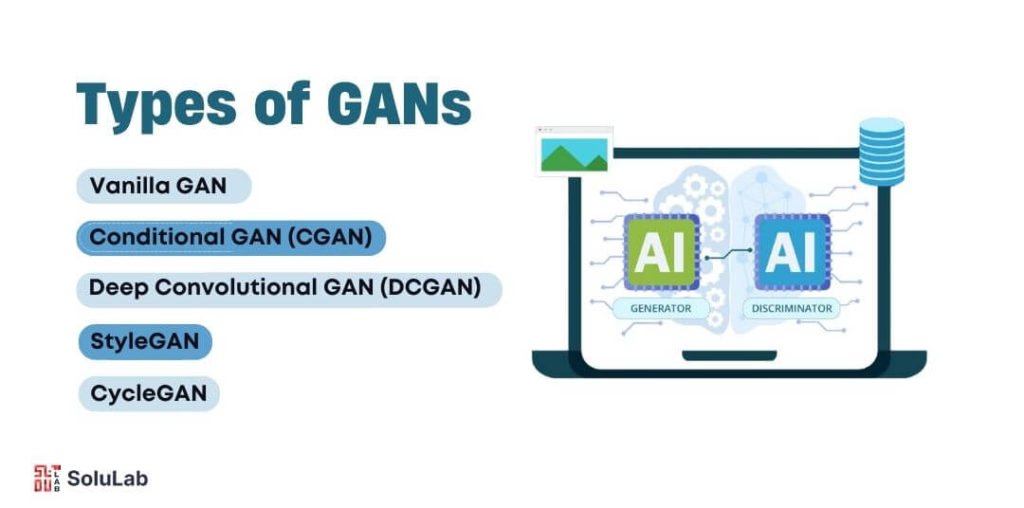
Over time, several variants of generative adversarial networks (GANs) have been developed, each tailored to excel in specific tasks. These variations build upon the core generative adversarial network architecture, enhancing capabilities and performance for various applications. Below are some of the most widely recognized types of GANs:
1. Vanilla GAN
The Vanilla GAN is the foundational model introduced by Ian Goodfellow and his team. This version consists of two core components: the generator and the discriminator, both of which engage in an adversarial game. The generator aims to produce synthetic data that mimics real data, while the discriminator works to differentiate between real and generated data. This basic architecture serves as the groundwork for many advanced GAN variations.
2. Conditional GAN (cGAN)
In a conditional GAN (cGAN), both the generator and the discriminator are conditioned on some extra information, such as a class label or other external input. This conditioning allows for more controlled data generation. For instance, instead of generating random images, a cGAN can generate images that belong to a specific category, like dogs or cats, based on the input label. This makes cGANs highly effective in scenarios where controlled outputs are required, such as text-to-image synthesis or targeted product design.
3. Deep Convolutional GAN (DCGAN)
Deep Convolutional GANs (DCGANs) are among the most popular variants due to their ability to generate high-quality images. In this model, both the generator and discriminator are built using convolutional neural networks (CNNs), which are particularly adept at processing visual data. The convolutional layers allow the Multimodal model to learn spatial hierarchies in the data, making it ideal for generating realistic generative adversarial networks images. DCGANs have been widely used in applications like image generation, video synthesis, and even creating artwork.
4. StyleGAN
StyleGAN is a sophisticated variant of GANs designed to generate ultra-realistic, high-resolution images with precise control over style and appearance. By separating high-level attributes (like pose) from low-level details (like textures), StyleGAN allows users to fine-tune the generated content’s appearance. This model has been especially useful in applications such as face generation and fashion design, where subtle changes in style can significantly impact the final output.
5. CycleGAN
CycleGAN offers a unique capability in the field of image-to-image translation without the need for paired training data. For instance, it can take an image from one domain, such as a photo of a horse, and convert it into an image from another domain, like a zebra, without needing paired images of horses and zebras. This makes CycleGAN particularly valuable in fields like image enhancement, where it can transform images between different styles or improve image quality in a fully unsupervised manner.
These variants highlight the flexibility and power of generative adversarial network architecture, each serving different use cases from generating generative adversarial networks images to transforming data across domains. GANs have become integral to fields like AI-powered art, content creation, and scientific research, constantly pushing the boundaries of what is possible with machine learning.
Examples of GANs
Generative Adversarial Networks (GANs) are powerful tools that have revolutionized data generation across various fields. From generating realistic images to crafting music, GANs have found applications in numerous domains. Here are some notable generative adversarial networks examples and applications:
- Image Generation: One of the most widely recognized applications of GANs is generating photorealistic images. Using models like a style-based generator architecture for generative adversarial networks (StyleGAN), GANs can create high-resolution portraits of fictional people. These images are generated entirely from random noise and resemble real photographs, showcasing the power of GANs in producing lifelike visuals.
- Image-to-Image Translation: GANs are also used in transforming images from one domain to another. Conditional generative adversarial networks (cGANs) like Pix2Pix and CycleGAN are examples of models that can convert a sketch into a full-colored image or translate a daytime photo into a nighttime scene. These networks learn how to map images from one domain to another, enhancing the capability to create highly specific outputs based on input conditions.
- Super-Resolution Imaging: Enhancing the quality of low-resolution images is another common use case of GANs. Generative adversarial networks PyTorch implementations, such as SRGAN (Super-Resolution GAN), are used to upscale images while preserving fine details. This has been particularly impactful in fields such as medical imaging and satellite photography, where image clarity is essential.
- Video Generation: Video generative adversarial networks are capable of producing realistic video content. VGAN (Video GAN), for instance, can generate short video clips or predict future frames based on a sequence of previous frames. This technology is valuable in predictive ensemble modeling, video synthesis, and creating visual content for industries such as entertainment and augmented reality.
- 3D Model Generation: GANs have evolved beyond 2D images into the realm of 3D model generation. Tools like efficient geometry-aware 3D generative adversarial nets have been developed to create realistic 3D models from 2D images or random input data. These models are particularly useful for gaming, virtual reality, and computer-aided design (CAD) applications, where accurate 3D representations are critical.
- Text-to-Image Generation: GANs like StackGAN take textual descriptions and generate corresponding images. For example, given a text input such as “a small bird with yellow wings and a red belly,” StackGAN can generate an image that closely matches the description, demonstrating how GANs can interpret textual information and turn it into a visual representation.
- Music Composition: GANs have also made inroads into the field of music. What is a generative adversarial network applied to music? In this case, GANs like MuseGAN are used to generate polyphonic music compositions, where multiple tracks are synthesized to harmonize together, resulting in full musical pieces. This opens the door to AI-driven music production and automated composition tools.
Applications of Generative Adversarial Networks (GANs)
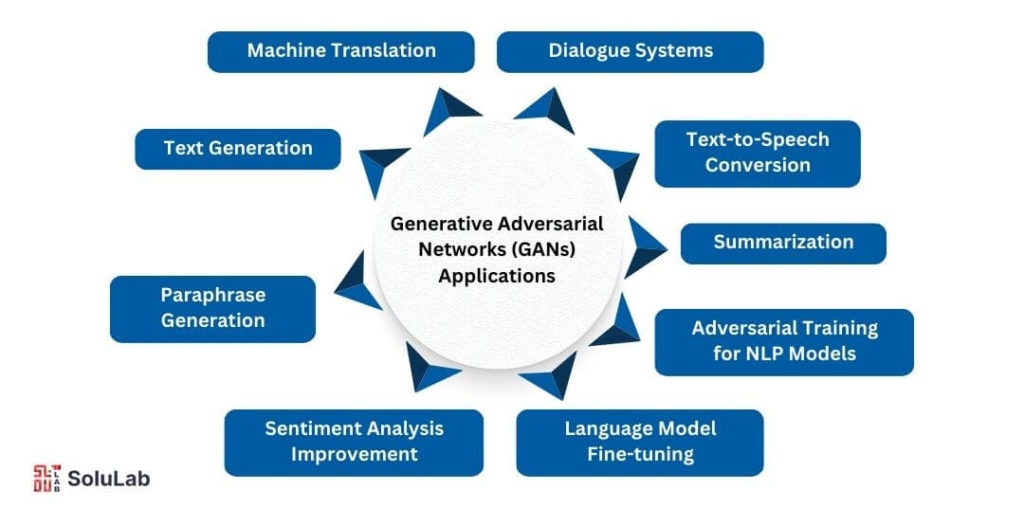
Generative Adversarial Networks (GANs), as introduced in the seminal Generative Adversarial Networks paper by Ian Goodfellow, have found significant applications in a variety of fields, including natural language processing (NLP). While traditionally used in image generation, GANs have also shown promise in generating human-like language and improving various language-related tasks. GANs consist of two neural networks—a generator and a discriminator—that work in opposition to each other. This adversarial process allows the generator to improve its ability to produce realistic outputs by learning from the discriminator’s feedback.
Here are some of the key applications of GANs in human language processing:
1. Text Generation: GANs can be used to generate coherent, human-like text, enabling the creation of narratives, dialogue systems, and creative content.
2. Paraphrase Generation: GANs are employed to create varied paraphrases of a given sentence, aiding in tasks like data augmentation and model training in NLP.
3. Sentiment Analysis Improvement: By generating adversarial examples, GANs help improve the robustness of sentiment analysis models, making them better at detecting subtle differences in sentiment.
4. Language Model Fine-tuning: GANs can be used to fine-tune small language models, helping improve fluency and coherence in text generation tasks.
5. Machine Translation: GANs improve the quality of machine translation by minimizing translation errors, especially for low-resource languages.
6. Text-to-Speech Conversion: GANs are applied to enhance the naturalness and intelligibility of speech synthesis models, making the generated speech sound more human-like.
7. Summarization: GANs can be used in text summarization tasks, where adversarial feedback helps generate concise yet informative summaries of large texts.
8. Dialogue Systems: GAN-based architectures are applied in chatbot and dialogue systems to create more engaging and contextually appropriate conversations with users.
9. Adversarial Training for NLP Models: GANs introduce adversarial examples during model training to make NLP models more resilient to errors and improve generalization.
While is LLM a type of generative adversarial networks that may arise as a common question, LLMs and GANs are fundamentally different in their architectures and use cases. However, the future may see these powerful tools being combined to further advance human language generation tasks.
Related: Comparison of Large Language Models
GANs vs. Autoencoders vs. Variational Autoencoders (VAEs)
Generative Adversarial Networks (GANs), Autoencoders, and Variational Autoencoders (VAEs) are three popular generative models used in the field of machine learning for tasks such as image generation, data compression, and reconstruction. While they all aim to generate or reconstruct data, they do so using different techniques and have distinct architectures, strengths, and weaknesses.
1. Generative Adversarial Networks (GANs)
GANs, introduced by Ian Goodfellow in the Generative Adversarial Networks paper (2014), are based on a two-network architecture: a generator and a discriminator. The generator’s job is to create realistic data samples, while the discriminator’s role is to evaluate whether the samples are real or generated. Through this adversarial process, both networks improve iteratively, with the generator becoming increasingly adept at producing high-quality data that can fool the discriminator.
- Strengths:
- Can generate highly realistic samples, especially in fields like image synthesis and art creation.
- Adversarial training improves the generator’s ability to produce sharp, detailed outputs.
- Popular for tasks such as super-resolution, image-to-image translation, and creative generation.
- Weaknesses:
- Training GANs can be unstable and difficult to optimize.
- Vulnerable to issues like mode collapse, where the generator produces limited varieties of data.
- Hard to measure convergence during training.
2. Autoencoders
Autoencoders are a type of neural network used primarily for data compression and reconstruction. The architecture consists of two parts: an encoder, which compresses the input data into a lower-dimensional representation (latent space), and a decoder, which reconstructs the data from this compressed form. The goal is for the reconstructed data to be as close as possible to the original input.
- Strengths:
- Simple and effective for dimensionality reduction and feature learning.
- Used for tasks such as denoising, anomaly detection, and data compression.
- Fast and stable to train compared to GANs.
- Weaknesses:
- Typically not as effective for generating highly realistic new data.
- Tends to produce blurry reconstructions when used for image generation.
- Does not have a stochastic sampling process, so it lacks diversity in generated samples.
3. Variational Autoencoders (VAEs)
VAEs are a probabilistic extension of autoencoders, designed to generate new data by learning a probability distribution over the latent space. Instead of learning a deterministic mapping from input to latent space like standard autoencoders, VAEs learn the parameters of a probability distribution, usually a Gaussian, from which new data samples can be generated. This makes VAEs capable of generating new, diverse data points rather than just reconstructing existing ones.
- Strengths:
- VAEs provide a principled approach to generative modeling by incorporating probabilistic sampling, allowing them to generate diverse and novel samples.
- More stable to train compared to GANs.
- Used in tasks like image generation, text generation, and latent space exploration.
- Weaknesses:
- Generated samples tend to be blurrier compared to GANs because VAEs prioritize learning the entire distribution over the data.
- The balance between reconstruction loss and the KL divergence (a measure of distribution difference) can be tricky, affecting model performance.
Comparison Summary
| Feature | GANs | Autoencoders | VAEs |
| Architecture | Generator + Discriminator | Encoder + Decoder | Encoder + Decoder + Latent Distribution |
| Generative Ability | Strong, can create high-quality data | Limited, focused on reconstruction | Strong, generates diverse samples |
| Training Difficulty | High (unstable, adversarial) | Low (simple loss minimization) | Moderate (balance between losses) |
| Output Quality | High-quality, sharp outputs | Typically lower-quality (blurry) | Lower-quality but diverse |
| Diversity of Outputs | Low if mode collapse occurs | Low (deterministic) | High (probabilistic sampling) |
| Common Use Cases | Image generation, super-resolution | Data compression, anomaly detection | Data generation, latent space learning |
Popular GAN Variants
Since their inception, Generative Adversarial Networks (GANs) have inspired numerous variants, each designed to overcome specific challenges or extend the original architecture’s capabilities. Leading AI consulting companies have embraced these advancements to offer cutting-edge solutions tailored to diverse industry needs. These variants, often implemented in deep learning frameworks like PyTorch Generative Adversarial Network libraries, have become essential in generating high-quality data for various tasks such as image synthesis, translation, and beyond.
-
Deep Convolutional GAN (DCGAN)
DCGAN replaces fully connected layers with convolutional layers, making GANs more stable and effective for image generation. It significantly improves the quality of generated images by capturing spatial hierarchies, making it a popular choice for visual data tasks, often implemented using PyTorch generative adversarial network libraries.
-
Conditional GAN (cGAN)
Conditional GANs allow control over the generation process by conditioning the model on additional data, such as labels or attributes. This approach is useful for generating specific types of images or objects, such as digits in MNIST or faces with particular features, providing a more targeted and flexible generation process.

-
Wasserstein GAN (WGAN)
WGAN addresses the instability and mode collapse in traditional GANs by using the Wasserstein distance for its loss function. This allows for more stable and reliable training, making it easier to generate diverse and high-quality data in tasks where traditional GANs struggle with variability.
-
Wasserstein GAN with Gradient Penalty (WGAN-GP)
WGAN-GP improves upon WGAN by replacing weight clipping with a gradient penalty, further enhancing training stability and performance. It is widely used for generating realistic and diverse images, particularly in scenarios where training GANs require precise control over the output quality.
-
Progressive Growing of GANs (PGGAN)
PGGAN generates high-resolution images by progressively increasing the resolution of both the generator and discriminator during training. This method ensures more stable training and allows the model to produce highly detailed images, making it ideal for tasks that require large, high-quality outputs like photorealistic faces.
-
CycleGAN
CycleGAN is designed for image-to-image translation tasks without needing paired data. It works by using a cycle consistency loss that ensures the generated image from one domain can be translated back to the original domain, preserving the essential characteristics of the input. CycleGAN is particularly useful for tasks like converting photos between different artistic styles or translating between animal species (e.g., horse to zebra).
-
StyleGAN
StyleGAN revolutionizes image generation by introducing a style-based generator, which separates high-level and low-level features. This allows for finer control over the attributes of generated images, such as the texture and structure. StyleGAN is most known for its success in generating photorealistic human faces and has become a benchmark for high-quality image synthesis, widely used in art, design, and media industries.
-
BigGAN
BigGAN takes the concept of scaling up GAN architectures by increasing model size and using larger datasets. This approach enhances the quality and diversity of the generated images, pushing the boundaries of what GANs can achieve in terms of realism and variety. BigGAN has been applied in tasks that require exceptionally high-fidelity images, such as detailed visual artwork and complex image generation tasks.
-
InfoGAN
InfoGAN introduces an unsupervised learning method for discovering interpretable latent representations. By maximizing the mutual information between latent variables and generated data, InfoGAN allows for the control of specific features in the generated outputs (e.g., rotation of objects or variations in facial expressions). This capability makes InfoGAN particularly useful in scenarios that require understanding and manipulating specific attributes in the data, such as feature learning and representation disentanglement.
How SoluLab Can Help in Generative Adversarial Network Development?
SoluLab is a leading technology solutions provider with extensive expertise in implementing Generative Adversarial Networks (GANs) across various industries. Whether you are looking to build the latest AI models for image generation, data augmentation, or complex machine learning tasks, SoluLab’s team of experts can help you design, develop, and deploy custom GAN solutions tailored to your business needs. We leverage advanced frameworks like PyTorch Generative Adversarial Networks and TensorFlow to build scalable, efficient, and high-quality models. With our deep knowledge of GAN variants such as DCGAN, WGAN, and StyleGAN, we ensure that your project achieves the highest levels of performance, stability, and precision. As one of the top AI development companies, SoluLab is committed to delivering innovative AI solutions that drive success.
By partnering with SoluLab, you can accelerate your AI initiatives and stay ahead of the competition with innovative GAN solutions. From prototyping and model optimization to full-scale deployment and post-launch support, we as an AI development company provide end-to-end services to help you harness the power of generative models. Ready to elevate your AI capabilities? Contact us today to learn how we can assist with your Generative Adversarial Network projects! Hire AI developers and let us bring your vision to life.
FAQs
1. What are Generative Adversarial Networks (GANs)?
Generative Adversarial Networks (GANs) are a class of machine learning models consisting of two neural networks—a generator and a discriminator—that work in opposition. The generator creates synthetic data (like images or text), while the discriminator evaluates the authenticity of the data. Through this adversarial process, GANs can generate realistic data resembling the original training set, making them popular for image generation, data augmentation, and more.
2. How do GANs differ from other generative models like Autoencoders or VAEs?
While GANs generate data through an adversarial process involving two networks, Autoencoders and Variational Autoencoders (VAEs) focus on compressing and reconstructing data. VAEs also introduce a probabilistic component for generating diverse outputs, but GANs are known for producing sharper and more realistic images. GANs tend to outperform Autoencoders and VAEs in tasks requiring highly detailed and realistic outputs, although they are harder to train.
3. What are the main challenges in training GANs?
Training GANs can be tricky due to issues like mode collapse (where the generator produces limited varieties of outputs), training instability, and difficulty in balancing the generator and discriminator. Careful tuning of hyperparameters, loss functions (e.g., WGAN’s Wasserstein loss), and architectural adjustments (such as using DCGAN or WGAN-GP) are common strategies to address these challenges.
4. What industries can benefit from using GANs?
GANs have applications in a wide range of industries. In media and entertainment, they are used for generating realistic images, videos, and even deepfakes. In healthcare, GANs are used for medical image synthesis and data augmentation to improve diagnosis accuracy. GANs are also applied in gaming, fashion design, art creation, and data privacy (through synthetic data generation).
5. How can SoluLab assist with Generative Adversarial Networks (GANs) development?
SoluLab offers end-to-end services for building custom GAN solutions tailored to your business needs. With expertise in frameworks like PyTorch Generative Adversarial Networks, our team can help you design, develop, and deploy state-of-the-art GAN models. Whether you need image generation, data augmentation, or AI-driven automation, SoluLab provides expert guidance and support from concept to deployment.
6. Is LLM a type of Generative Adversarial Networks?
In the field of artificial intelligence, Generative Adversarial Networks (GANs) and Large Language Models (LLMs) have different but related functions. GANs are mainly used for producing genuine images and other data kinds, whereas LLMs are excellent at natural language processing problems.