Machine learning has grown into a vital tool for enterprises and individuals, allowing us to capitalize on the power of data, streamline processes, make better-informed decisions, and promote innovation across a wide range of areas, influencing the world we live in today. According to Fortune Business Insight, the worldwide machine learning (ML) industry is predicted to increase from $21.17 billion in 2022 to $209.91 billion by 2029, with a CAGR of 38.8% throughout the forecast period. MLOps, on the contrary, has evolved as a transformational field that combines machine learning with software engineering.
MLOps provides a systematic way to oversee the whole lifecycle of machine learning models, from development and training to deployment and ongoing maintenance, in a world where data and GenAIOPs-driven insights are driving the world more and more. Through the integration of industry-best practices from data science, DevOps, and software engineering, MLOps enables enterprises to optimize and grow their machine learning processes while maintaining scalability, reproducibility, and dependability. Businesses can unleash the full potential of their machine learning projects with large language models and MLOps, which will spur innovation, enhance model performance, and have a significant influence on the real world.
In this blog, we will make the readers understand how to build an MLOps pipeline and the machine learning operations in more depth. So, without any further ado, let’s get started!
What is MLOps?
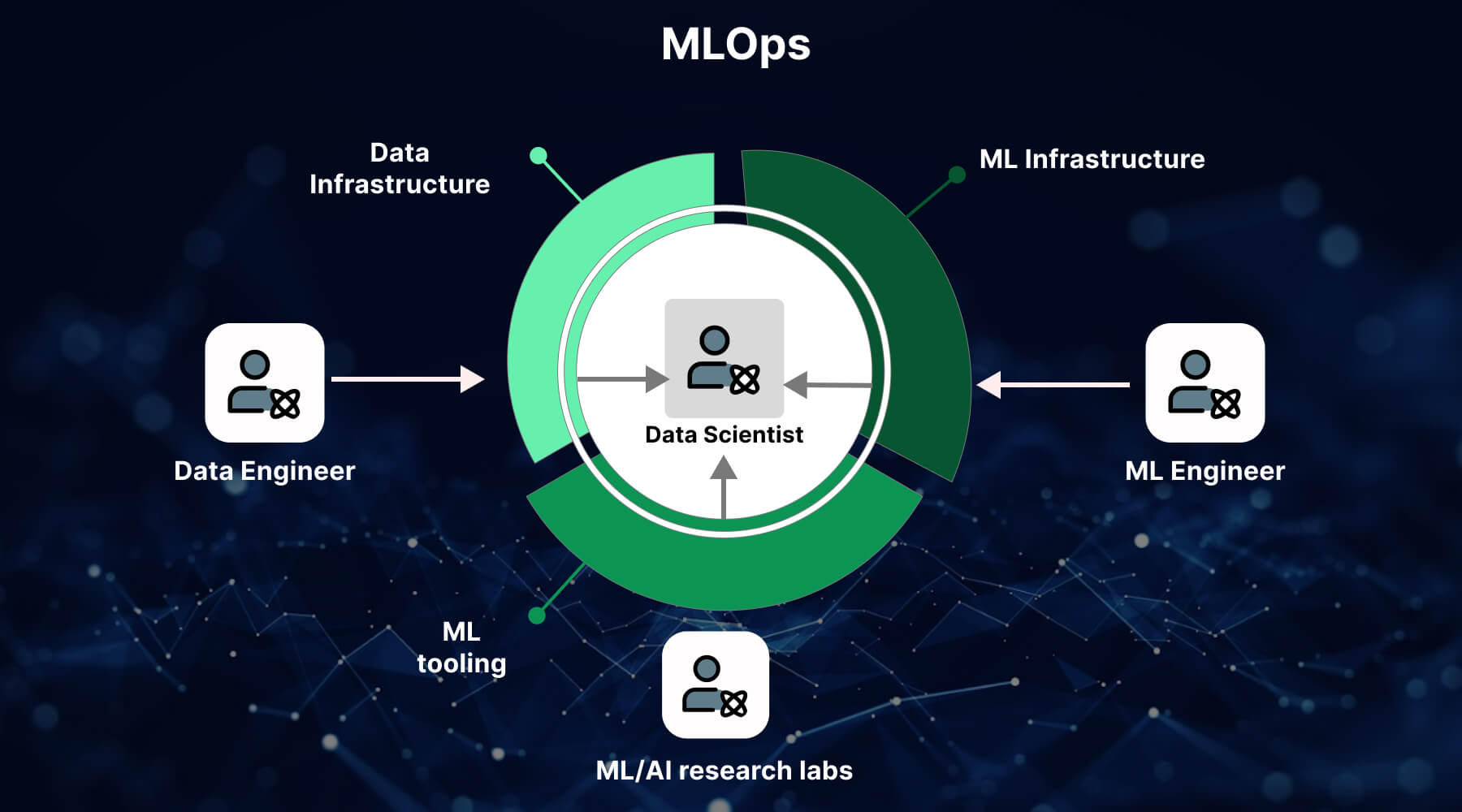
MLOps, or machine learning operations, is a collection of practices and methods designed to streamline the entire lifecycle of machine learning models within production environments. This encompasses the iterative processes of model development, deployment, monitoring, and maintenance, along with the integration of models into operational systems to ensure reliability, scalability, and optimal performance. In some cases of GenAI services, MLOps is solely used for deploying machine learning models. However, many organizations leverage MLOps throughout various stages of the ML lifecycle, including Exploratory Data Analysis (EDA), data preprocessing, model training, and more.
Based on DevOps principles, which were created to improve collaboration between software development teams (Devs) and IT operations teams (Ops), MLOps applies these same concepts to the machine learning workflow. In an MLOps pipeline, the team often includes data scientists, machine learning engineers, software developers, and IT operations professionals. Data scientists organize and analyze datasets using AI and ML algorithms, while Private LLM engineers use structured, automated processes to run the data through models. The overall aim of MLOps is to reduce inefficiencies, increase automation, and produce deeper, more trustworthy insights.
Optimizing the development, deployment, monitoring, and maintenance of machine learning models requires the use of tools, methodologies, and best practices to ensure consistency, scalability, and performance in practical applications. What is the MLOps pipeline? It’s a process that aims to bridge the gap between data scientists, developers, and operations teams, ensuring smooth and effective deployment of machine learning models into production environments. MLOps lies in creating a seamless, automated workflow for managing AI and ML in data integration and beyond, enabling businesses better to harness machine learning’s potential in real-world settings.
MLOps vs DevOps- What’s the Difference?
While both MLOps and DevOps aim to streamline workflows and enhance collaboration between development and operations teams as per AI use cases, their focus and applications differ significantly. Here is the brief difference between the two:
| Aspect | DevOps | MLOps |
| Development Focus | Focuses on developing, testing, and deploying traditional software applications. | Centers on creating, training, and deploying machine learning models. |
| End Product | A deployable software unit (e.g., an application or interface). | A serialized machine learning model that makes predictions based on data. |
| Version Control | Tracks change in code and artifacts, with limited metrics for tracking. | Tracks code, training datasets, hyperparameters, model artifacts, and performance metrics for each experiment. |
| Reusability | Emphasizes reusable and automated processes across projects. | Encourages consistent, reusable workflows for model training and deployment to maintain accuracy across projects. |
| Automation | Automates CI/CD pipelines for smooth software delivery. | Automates model training, retraining, and deployment while managing ongoing model performance. |
| Monitoring | Continuous monitoring ensures reliability, though the software does not degrade over time. | Requires continuous monitoring as ML models degrade with evolving real-world data, needing retraining to remain effective. |
| Infrastructure | Relies on cloud technologies, Infrastructure-as-Code (IaC), and CI/CD tools. | Uses cloud infrastructure with resources like deep learning frameworks, GPU support, and large data storage. |
| Performance Decay | No performance degradation once the software is deployed. | ML models can degrade as new data is encountered, necessitating continuous retraining and updates |
MLOps Pipeline Architecture
A well-thought-out end-to-end machine learning pipeline architecture is essential for model creation, deployment, and maintenance in Machine Learning Operations (MLOps). The MLOps pipeline and AI development ensure efficiency, teamwork, and flexibility by streamlining the whole lifecycle. The main elements and architectural factors of a simple MLOps pipeline are broken down as follows:
-
Data Gathering and Ingestion
Most machine learning pipelines begin with the extraction of raw data from several sources and its input into the system. This stage guarantees a thorough and pertinent dataset for the model’s ensuing training. Data connections, ingestion scripts, and preparation techniques are a few examples of components that significantly influence the quality of data that is made accessible for machine learning.
-
Preparing Data and Feature Engineering
The pipeline moves into feature engineering and data preparation after data collection. To produce an organized and enhanced dataset appropriate for model training, a variety of data transformation techniques, such as feature extraction, normalization, and cleaning, are used for the raw data at this step. The efficacy of this stage, where data pretreatment scripts and feature engineering techniques are essential components, frequently determines the model’s success.
-
Model Development and Training
The pipeline then goes on to model construction and training after data transformation. In this stage, the machine learning model is trained, suitable methods are chosen, and hyperparameters are optimized. Three essential elements shape the predictive power of the model: experimental frameworks, model configuration files, and training scripts.
-
Model Assessment and Validation
After training, the AI Applications model is assessed and validated to make sure its output satisfies predetermined standards. In this stage, the model is evaluated using training and testing sets, and any required adjustments are made after comparing the output to predicted outcomes on unknown data. The thorough evaluation of the model is aided by comparison tools, validation metrics, and evaluation scripts.
-
Model Implementation
The learned model is incorporated into a production environment for batch or real-time predictions following successful training and validation. A fast transition from development to deployment is made possible by deployment scripts, containerization solutions like Docker, and a seamless interface with serving infrastructure.
-
Observation and Recordkeeping
To ensure maximum usefulness, it is essential to log pertinent data and monitor the model’s performance continuously. To quickly identify abnormalities and take care of possible problems, this step entails putting monitoring tools, logging structures, and alerting systems into place.
-
Iteration of the Model and Feedback Loop
A feedback loop is incorporated into the MLOps pipeline to get information from deployed models. Iterative improvements are made possible by this input, which helps the model adjust to shifting data patterns and gradually increase its forecast accuracy. This is made possible by automated retraining procedures and version control.
-
Governance and Compliance
Governance and compliance procedures are incorporated into the MLOps pipeline to ensure compliance with business and regulatory standards. To promote accountability and transparency, this entails putting compliance frameworks into place, keeping thorough audit trails, and documenting procedures.
-
Continuous Deployment/Continuous Integration (CI/CD)
Since the pipeline makes use of continuous integration and continuous deployment (CI/CD) procedures, automation is a major area of attention during this phase. By automating testing, integration, and deployment, these procedures guarantee the safe and effective release of models into operational settings.
-
Resource Management and Scalability
Scalability and resource management become crucial factors when the pipeline must manage fluctuating demands. The pipeline’s capacity to meet a range of computing needs is facilitated by scalability tools, resource allocation strategies, and effective use of cloud resources.
Why are MLOps Necessary?
The proliferation of automated decision-making applications and the growing size and complexity of data provide a number of technological obstacles to the development and implementation of machine learning (ML) systems. This is where the machine learning engineering culture known as MLOps, which aims to optimize these systems, comes in.
It is necessary to comprehend the ML system lifecycle, which encompasses several teams inside an organization, in order to comprehend MLOps. The business development or product team sets goals and key performance indicators (KPIs) first.
MLOps tackles several significant issues. First off, there aren’t enough data scientists who are skilled at creating and implementing scalable online applications. A new position called “ML engineer” has evolved to close this gap, combining DevOps and data science expertise. Thirdly, poor communication between the business and technical teams frequently results in project failures. Establishing a shared language is essential for promoting cooperation.
Finally, considering the opaque nature of these “black-box” systems, it is critical to evaluate the risk related to the possible failure of these ML/DL systems. The financial ramifications of, say, a misguided YouTube video recommendation are far different from those of falsely reporting an innocent individual for fraud. MLOps aims to achieve this equilibrium, resulting in a less hazardous and more effective machine learning system.
Why Do We Need MLOps?
The increasing scale and complexity of data, along with the growing use of automated decision-making applications, present various technical challenges in building and deploying machine learning (ML) systems. This is where MLOps comes into the picture, offering a machine learning engineering culture aimed at optimizing these systems.
Understanding MLOps starts with recognizing the lifecycle of ML systems, which involves multiple teams. The process begins with the business development or product teams defining clear objectives and KPIs, setting the foundation for the work ahead.
The data engineering team is then responsible for acquiring and preparing the data, while the data science team focuses on building the ML models. One significant challenge is the shortage of data scientists skilled in developing scalable web applications, leading to the rise of the ML engineer role, which combines expertise from both data science and DevOps.
Additionally, as business objectives shift and data evolve, LLMOps play a critical role in helping ML models adapt to these changes. Continuous model training and ensuring AI governance are essential for maintaining performance standards.
Another major hurdle is the communication gap between technical and business teams, which often results in project failures. MLOps Consulting Services emphasizes the importance of fostering collaboration to bridge these gaps and achieve successful deployments.
Finally, assessing the risk associated with ML/DL systems is crucial, especially given their “black-box” nature. Ensuring that the right balance between efficiency and risk is maintained is vital, especially in high-stakes environments where mistakes could have significant consequences. LLM use cases also demand careful risk management to ensure their practical applications are reliable and safe.
What is MLOps Pipeline?
Machine learning pipelines are a sequence of interconnected procedures designed to automate and streamline the development of machine learning models. These pipelines can include various stages, such as data extraction, preprocessing, feature engineering, model training, evaluation, and deployment. The primary goal of a machine learning pipeline is to automate the entire model development process, ensuring consistency, scalability, and maintainability throughout the lifecycle.
These pipelines are crucial in managing the complexity of machine learning projects, allowing data scientists to experiment systematically with data before implementing treatment methods, feature engineering, and algorithms. With the help of MLOps pipelines, professionals can ensure smoother workflows, enabling efficient experimentation and deployment of models in production environments.
Pipelines consist of organized, automated tasks that streamline workflows across industries, particularly in machine learning and data orchestration. Through MLOps consulting services, organizations can optimize these workflows, ensuring that machine learning models are deployed effectively and maintained to meet business needs.
Incorporating both large and small language models within machine learning pipelines enhances the capability to process different data types and improve model performance. These models provide scalable solutions for a variety of machine learning tasks, allowing businesses to leverage AI more effectively.
What is the Process of MLOps?
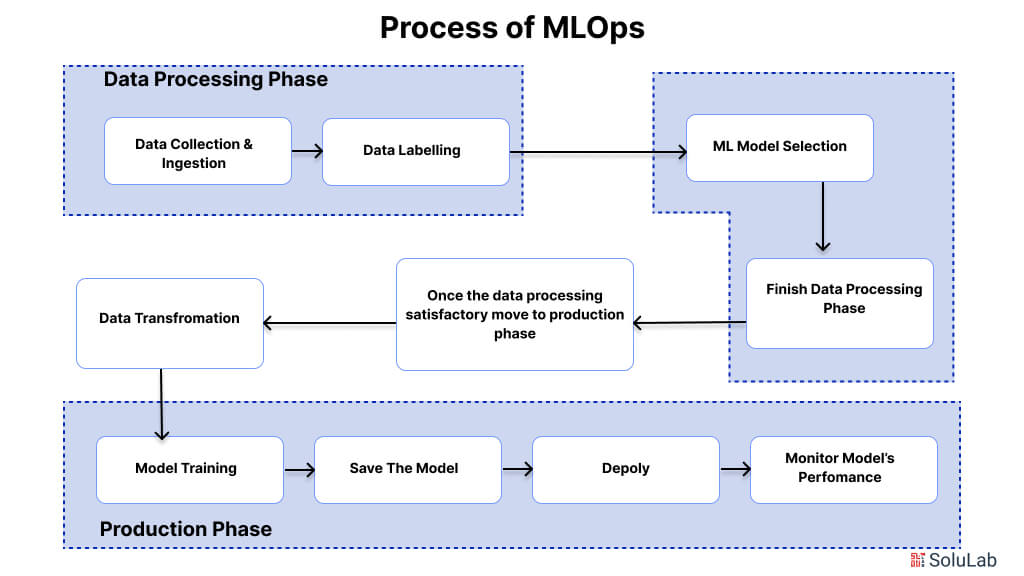
Let us understand the MLOps process in detail. The workflow has two separate phases: an experimental phase and a production phase. There are specific workflow stages for each component of the workflow.
A. Experimental Phase
This phase is divided into three stages, discussed below:
Stage 1: Problem Identification, Data Collection, and Analysis
The first step in MLOps involves defining the problem to be solved and collecting data for training the machine learning model. For instance, in a fall detection application, hospital video data is collected from cameras in patient rooms and hallways. These video feeds serve as input for the model. After preprocessing and labeling, the system will detect falls and alert hospital staff. Key sub-stages include:
- Data Collection and Ingestion: Collected video data is stored in a data warehouse, cleaned, normalized, and processed to ensure consistency. Once the data is ready, it is ingested into the system, using methods like loading into data lakes or real-time streaming platforms.
- Data Labeling: This involves tagging video data to identify patient falls. Data scientists annotate short segments of videos that show patient behaviors, like falling, to train the model accurately.
Stage 2: Machine Learning Model Selection
In this stage, machine learning algorithms are evaluated and tested to find the best model for the task. Data scientists experiment with techniques like motion analysis to detect patterns associated with falls. By iterating through multiple models and parameter configurations, the ideal model is selected for real-time fall detection.
Stage 3: Model Training and Hyperparameter Tuning
Data scientists run experiments to train the model, testing various hyperparameters and documenting their findings. Cloud platforms are often used to manage multiple test iterations and improve model performance. Once the experiments yield the desired results, the process moves to the production phase.
B. Production Phase
The goal of this phase is to deploy a fully tested ML application in a live environment.
Stage 1: Data Transformation
The complete dataset is used to train the model during this stage. Data parallelism or model parallelism may be used to speed up processing when working with large datasets.
Stage 2: Model Training
Scalable methods, such as data parallelism, are employed to train the model on large datasets. In this method, the dataset is divided into smaller batches, which are processed simultaneously across multiple devices, ensuring efficient learning.
Stage 3: Model Serving
Once the model is ready, it is served to the production environment. A/B testing and canary testing are conducted to compare different model versions. These tests help identify the most stable and high-performing models for deployment.
Stage 4: Performance Monitoring
After deployment, the model’s performance must be continuously monitored. Drift monitoring, which checks for changes in data distribution or model accuracy, is crucial to ensure long-term success.
How to Build an MLOps Pipeline?
Building an MLOps pipeline involves several stages that streamline the deployment, monitoring, and management of machine learning models. To build an MLOps pipeline, it’s essential to integrate both machine learning and DevOps practices, ensuring continuous integration, delivery, and scalability.
Step 1: Data Collection and Processing
The first step in creating an MLOps pipeline is gathering and preprocessing data. The data should be cleaned, labeled, and prepared for model training. This phase often involves data versioning and setting up automated workflows to ensure consistency in training datasets.
Step 2: Model Development and Training
The next step involves building the model architecture and training it on the processed data. Utilizing tools like TensorFlow or PyTorch, data scientists can iterate on different models. Automated training pipelines should be established to enable quick retraining as new data becomes available.
Step 3: Model Validation and Testing
Once trained, the model must undergo validation and testing to ensure accuracy and reliability. Metrics like precision, recall, and F1-score can be evaluated. Automated testing ensures that only high-performing models are promoted to the next stage.
Step 4: Continuous Integration and Deployment
To build an MLOps pipeline, continuous integration (CI) plays a critical role. The model, along with its dependencies, is integrated into a deployment pipeline using tools like Jenkins or GitLab CI/CD. This stage ensures that the model can be deployed into production environments efficiently.
Step 5: Model Monitoring and Maintenance
Once the model is deployed, it’s crucial to monitor performance in real-time. Tools like Prometheus and Grafana help track metrics such as latency, prediction accuracy, and drift. Maintenance is required to retrain or replace models when performance declines due to evolving data patterns.
Step 6: Conversational AI Integration
If your use case involves conversational AI, integrate natural language processing (NLP) models as part of the pipeline. These models enable chatbots, virtual assistants, and other AI-driven conversations to process text and speech. Automated retraining pipelines are key in conversational AI systems to keep improving interactions based on user feedback.
By following these steps, organizations can efficiently build an MLOps pipeline that supports continuous deployment, monitoring, and scaling of machine learning models, especially when working with conversational AI or other data-driven applications.
Best Practices for Building an MLOps Pipeline
To build an effective MLOps pipeline that ensures scalability and reliability, organizations should follow several key best practices. Here are some of the essential practices:
1. Automate Data Pipeline and Model Training
Leveraging business process automation is crucial to automate data collection, cleaning, and feature engineering. This ensures that models are trained consistently on the latest data without manual intervention, speeding up the development cycle and minimizing human error.
2. Establish Continuous Integration and Delivery (CI/CD)
Implementing CI/CD for machine learning operations allows models to be automatically tested, validated, and deployed after training. Continuous integration ensures that every change to the model or data pipeline is tested, while continuous delivery enables rapid and reliable model updates in production environments.
3. Leverage Model Monitoring and Alerting
Monitoring models in real-time is vital to detect performance drift or data inconsistencies. Implement automated alerts for metrics like accuracy, latency, and data drift, so that teams can quickly respond and retrain models when performance issues arise.
4. Utilize Robotic Process Automation (RPA) for Efficiency
Integrating robotic process automation into the MLOps pipeline can streamline administrative and repetitive tasks such as infrastructure provisioning and model deployment. RPA can ensure that tasks are consistently performed and helps reduce the workload on data scientists and engineers.
5. Ensure Model Versioning and Reproducibility
Version control for both models and data is essential for maintaining reproducibility in the development process. By keeping track of model versions and their corresponding datasets, teams can trace the performance of different iterations and ensure consistency in machine learning operations.
6. Focus on Security and Compliance
Ensure that your MLOps pipeline adheres to security best practices, including data encryption, access control, and compliance with industry regulations. This is particularly important when handling sensitive data or deploying models in industries such as healthcare and finance.
By adopting these best practices, organizations can build robust MLOps pipelines that support automation, continuous improvement, and high-performance machine learning models.
How SoluLab Can Be Beneficial in Developing MLOps Pipeline?
Developing an efficient MLOps pipeline often comes with challenges such as managing complex data workflows, ensuring model scalability, and maintaining continuous integration and monitoring systems. Many businesses struggle with handling these tasks due to the lack of skilled resources and the technical complexity involved. SoluLab, a leading AI development company, offers end-to-end MLOps solutions that streamline these processes. From automating data pipelines to building robust CI/CD systems for machine learning operations, , A machine learning development company like SoluLab ensures that your models remain scalable, accurate, and secure, effectively reducing the risk of performance drift and operational bottlenecks.
When you hire AI developers from SoluLab, you gain access to a team of experts proficient in addressing common pain points like inefficient model deployment and a lack of real-time monitoring. Our team builds pipelines that are fully automated, helping you scale your machine-learning models and deploy them seamlessly into production. With tailored MLOps solutions designed to meet your specific business needs, we ensure faster time-to-market and long-term performance. Contact us today to learn how we can help you build a successful MLOps pipeline!

FAQs
1. What is an MLOps pipeline, and why is it important?
A comprehensive framework designed to integrate machine learning (ML) processes with DevOps practices, AI developers can facilitate the end-to-end management of ML models, which streamlines operations, reduces manual errors, and enables scalable and efficient deployment of ML models
2. What are the main components of an MLOps pipeline?
The main components of an MLOps pipeline include several key stages such as data collection and processing, model development, continuous integration, and deployment (CI/CD), monitoring and maintenance, and automation tools such as business process automation and robotic process automation.
3. How can I ensure the quality of models in an MLOps pipeline?
Implementing automated testing and validation processes helps evaluate model performance on a variety of metrics before deployment. Continuous monitoring is also essential to detect any performance drift or issues after the model is in production.
4. What challenges might I face when building an MLOps pipeline?
Building an MLOps pipeline presents several challenges, including integration complexity, and managing large volumes of data, models may experience performance degradation over time, known as model drift, and scalability is another concern.
5. How can SoluLab assist in developing an MLOps pipeline?
SoluLab can provide valuable assistance in developing an MLOps pipeline our dedicated developers specialize in designing and implementing pipelines that automate data workflows, model training, and deployment processes.


