

A subset of machine learning known as multimodal models is capable of processing and analyzing several data kinds, or modalities, at once. Because it can increase accuracy and performance in a variety of applications, this method is gaining popularity in the field of artificial intelligence.
Multimodal models can enable more complex activities and offer a more thorough comprehension of data by integrating many modalities, such as text, voice, and visuals.
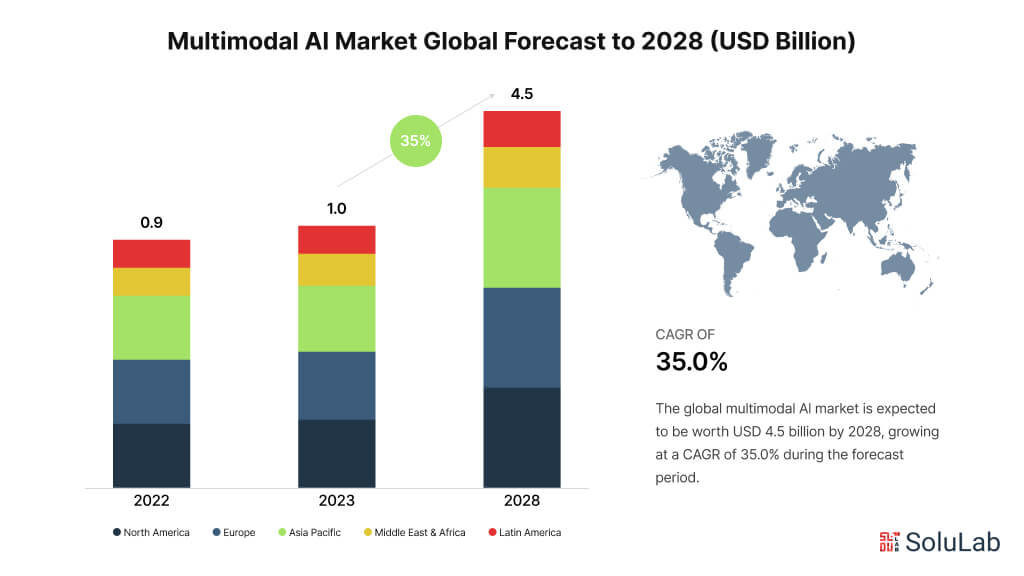
According to reports, as the need to examine large amounts of unstructured data grows, the multimodal AI industry is expected to rise by 35% a year to reach USD 4.5 billion by 2028.
Because deep learning can handle huge and complicated datasets, it is especially well-suited for multimodal models. Furthermore, they frequently use advanced techniques like transfer learning and representation learning to enhance performance and extract valuable characteristics from data.
Let’s explore it in detail!
What are Multimodal Models?
AI deep-learning models that process many modalities, such as text, audio, video, and images, at the same time and produce results are known as multimodal models. Mechanisms for integrating multimodal data gathered from many sources are included in multimodal frameworks to provide a more thorough and context-specific understanding.
Multimodal AI Models: Comparing Combining Models vs. Multimodal Learning
Artificial Intelligence, Multimodal AI employs two distinct approaches: model fusion and multimodal foundation models. Although these concepts may seem similar at first glance, they possess fundamental differences that set them apart as unique technologies. To gain a comprehensive understanding, let’s delve into the details of each approach:
| Aspect | Combining Models | Multimodal Learning |
| Definition | Integrates multiple models to improve the performance of a primary model | Enables AI to process and understand multiple data types (text, image, audio, video) |
| Goal | Enhance prediction accuracy by blending strengths of various models | Achieve a comprehensive understanding of context by fusing different modalities |
| Techniques Used | Ensemble models, Stacking, Bagging | Deep neural networks for independent modality processing and fusion |
| Example Use Case | Combining NLP models for sentiment analysis | Using image + text for visual question answering |
| Working Principle | Models are trained separately and then combined at the decision level | Inputs are processed in parallel and fused into a unified representation |
| Data Type Handling | Typically handles the same type of data across different models | Handles and combines heterogeneous data types |
| Analogy | A panel of experts voting on a final decision | Like human senses (sight, sound, touch) working together to perceive reality |
| Strengths | Increases robustness, reduces overfitting, improves generalization | Offers deeper context, handles diverse data, mirrors human-like understanding |
| Complexity Level | Moderate | High – due to handling of modality heterogeneity and integration challenges |
| Challenges | Model compatibility, overfitting in meta-models, and computational cost | Modality alignment, fusion strategy, increased computational requirements |
| Foundation Architecture | Random Forest, SVM + Neural Network ensemble | Vision-Language Transformers, CLIP, FLAVA, Gemini |
| Data Representation | Focused on prediction-level output combination | Unified feature representation across modalities |
| Application Areas | Sentiment analysis, fraud detection, recommendation systems | Image captioning, autonomous driving, virtual assistants |
| Interaction Focus | Aggregating predictions | Understanding modality relationships (e.g., semantic, statistical, response-based) |
| Future Direction | Enhanced meta-learning models | Larger foundation models with better modality fusion and reasoning |
Benefits Of Multimodal AI Models
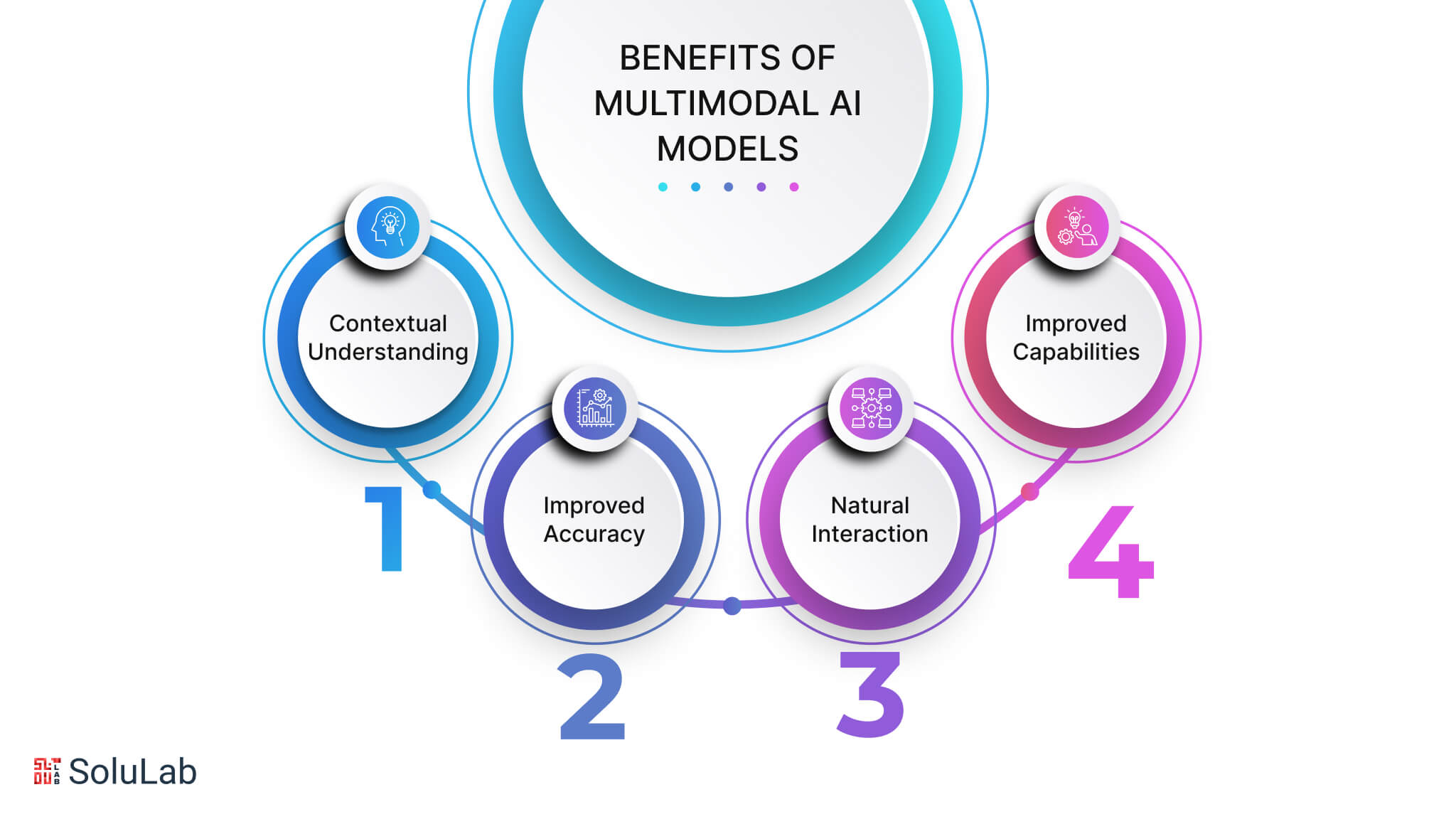
Some of the most notable benefits of utilizing multimodal AI models include:
1. Understanding Context
Multimodal AI systems excel in understanding words and phrases in natural language processing (NLP) by examining related concepts and keywords. This ability helps models understand sentences and respond appropriately. When integrated with multimodal AI models, NLP models can use linguistic and visual data to better understand the context.
2. Improved accuracy
Large multimodal models improve accuracy by mixing text, images, and videos. They evaluate input data more thoroughly, improving performance and prediction across tasks. Multimodal models improve picture captioning by using many modalities. They improve natural language processing by combining facial and speech recognition to better understand speaker emotions.
3. Natural Interaction
AI models used to be limited to text or speech input, making it difficult for them to engage naturally with users. However, multimodal language models can employ text, voice, and visual clues to better grasp user wants and intents. In a virtual assistant, a multimodal large language model system can comprehend user commands using text and audio recognition.
4. Better Capabilities
Multimodal models improve AI by using image, text, and audio. They help AI systems accomplish more tasks accurately, efficiently, and effectively. Multimodal large language models that recognize faces and audio can identify people. The model can distinguish things and people with similar voices and appearances by assessing audio and visual signals.

How Do Multimodal Models Work?
To simplify the understanding of the multimodal AI architecture’s functionality for various input types, we have provided real-life examples:
1. Generation of text-to-image and image description
The decade saw revolutionary models like GLIDE, CLIP, and DALL-E. These amazing models can produce visuals from text descriptions and describe existing photos. OpenAI’s CLIP model encodes text and images separately. These encoders are trained on large datasets to correlate images and descriptions. CLIP also uses multimodal neurons that activate when the model encounters a picture and its text description, representing coupled multimodal large language models.
In comparison, DALL-E, a popular GPT-3 model with up to 13 billion parameters, provides numerous prompt-aligned pictures. After CLIP evaluates these images, DALL-E produces exact and detailed outputs. CLIP is used by GLIDE to evaluate created images like DALL-E. GLIDE creates more realistic visuals using a diffusion model than DALL-E.
2. Visually answering questions
Models must accurately answer questions based on images in Visual Question Answering (VQA). Microsoft Research pioneers VQA innovations. METRE, for example. This framework uses sub-architectures for vision, decoding, text, and a huge multimodal model. Unified Vision-Language Pretrained Model VQA is another notable method.
VLMo learns with dual, fusion, and modular transformer network encoders. The model’s network has self-attention layers and modality-specific expert blocks. This architecture provides great flexibility for fine-tuning the model to specific activities or use cases.
3. Image-to-text or text-to-image search
Web search is transformed by multimodal language models. Carnegie Mellon University and Microsoft data scientists and developers methodically created the WebQA dataset. When used properly, this dataset helps web-search models find text and image-based sources that answer user queries. However, the model needs several sources to make accurate predictions. After “reasoning” with these numerous inputs, the model responds to the first inquiry in plain language.
Google’s ALIGN model trains text (BERT-Large) and visual (EfficientNet-L2) encoders using alt-text data from internet photos. The multimodal architecture merges encoder outputs using contrastive learning. This produces robust models with multimodal representation capabilities that can power online searches across modalities without training or fine-tuning.
4. Video-Language Modeling
AI systems struggle with resource-intensive video-language modeling tasks. Experts have created multimodal foundation models that can handle video data to solve this problem and boost AI’s natural intelligence. Microsoft’s ClipBERT-based Project Florence-VL is an example. ClipBERT applies transformer models and CNNs to minimally sampled video frames.
SwinBERT and VIOLET use Sparse Attention and token modeling to perform well in video-related tasks, including question answering, captioning, and retrieval. Transformer-based architecture unites ClipBERT, SwinBERT, and VIOLET. This architecture is usually combined with parallel learning modules to extract video data from several modalities and join it into a multimodal representation.
How Do Multimodal Models Work For Different Types Of Inputs?
To simplify the understanding of the multimodal AI architecture’s functionality for various input types, we have provided real-life examples:
-
Text-to-image Generation And Image Description Generation
Several groundbreaking models of the decade include GLIDE, CLIP, and DALL-E. These remarkable models have the ability to generate images based on text descriptions and provide meaningful descriptions of existing images. OpenAI’s CLIP model employs separate encoders for text and images. These encoders are trained on vast datasets to establish correlations between specific images and their corresponding descriptions within the dataset. Additionally, CLIP utilizes multimodal neurons that become active when the model encounters an image and its matching text description, signifying a representation of combined multimodal large language models. In contrast, DALL-E, a popular variant of the GPT-3 models with up to 13 billion parameters, generates multiple images aligned with a given prompt. Subsequently, CLIP assesses these images, allowing DALL-E to produce precise and detailed outputs. Similar to DALL-E, GLIDE also leverages CLIP to evaluate generated images. However, unlike DALL-E, GLIDE employs a diffusion model to create more accurate and realistic images.
-
Visual Question Answering
In Visual Question Answering (VQA), models must answer questions correctly based on a given image. Microsoft Research stands out as a leader in developing innovative approaches for VQA. Take METRE, for example. This framework utilizes multiple sub-architectures for vision encoding, decoding, text encoding, and large multimodal model. Another notable approach to VQA is the Unified Vision-Language Pretrained Model (VLMo). VLMo employs various encoders, including a dual encoder, fusion encoder, and modular transformer network, for learning. The model’s network consists of multiple self-attention layers and blocks with modality-specific experts. This design offers exceptional flexibility when fine-tuning the model, allowing for precise adaptations to specific tasks or use cases.
-
Image-to-text Search And Text-to-image
The advent of multimodal language models learning brings a paradigm shift to the world of web search. A prominent illustration is the WebQA dataset, meticulously crafted by data scientists and developers from Carnegie Mellon University and Microsoft. When harnessed effectively, this dataset empowers web-search models to pinpoint text and image-based sources that contribute to the resolution of a user’s query. However, the model’s efficacy relies on multiple sources to deliver precise predictions. Subsequently, the model undertakes the task of “reasoning” with these multiple sources, culminating in a natural language response to the initial query. In a similar vein, Google’s ALIGN (Large-scale ImaGe and Noisy-Text Embedding) model leverages alt-text data extracted from internet images to train distinct text (BERT-Large) and visual (EfficientNet-L2) encoders. The multimodal architecture employed fuses the outputs of these encoders through contrastive learning. This process yields robust models with multimodal representation capabilities, enabling them to power web searches across diverse modalities without the need for additional training or fine-tuning.
-
Video-language Modeling
The resource-intensive nature of video-language modeling tasks poses substantial challenges for AI systems. To address this issue and advance toward AI’s natural intelligence, experts have developed multimodal foundation models capable of handling video-related information. One notable example is Project Florence-VL by Microsoft, which features the ClipBERT model. ClipBERT combines transformer models with convolutional neural networks (CNNs) applied to sparsely sampled video frames. Other iterations of ClipBERT, such as SwinBERT and VIOLET, employ Sparse Attention and Visual-token Modeling to achieve state-of-the-art performance in video-related tasks like question answering, captioning, and retrieval. ClipBERT, SwinBERT, and VIOLET share a common transformer-based architecture. This architecture is typically integrated with parallel learning modules that enable the models to extract video data from multiple modalities and fuse it into a unified multimodal representation.
Use Cases Of Multimodal Models

Across various sectors, several companies have recognized the potential of multimodal AI and have integrated it into their digital transformation strategies. Here is a glimpse into some of the most noteworthy applications of multimodal AI:
1. Healthcare And Pharma
In the healthcare, the rapid adoption of technology to enhance service delivery is a testament to the sector’s commitment to innovation. Among these advancements, Hybrid AI stands out as a transformative force, offering hospitals the potential for more precise diagnoses, improved treatment outcomes, and tailored patient care plans.
At the heart of large multimodal models capabilities lies its ability to analyze diverse data modalities such as symptoms, medical background, imaging data, and patient history. This enables healthcare professionals to make informed diagnostic decisions with greater speed and accuracy. For instance, in complex conditions, large multimodal models can analyze medical images like MRIs, X-rays, and CT scans, providing a holistic view of the patient’s condition when combined with clinical histories and patient data. This comprehensive approach enhances diagnostic precision, empowering medical professionals to deliver optimal care.
Beyond diagnostics, the pharmaceutical sector also stands to benefit from multimodal AI’s prowess. By leveraging this technology, pharmaceutical companies can enhance drug discovery processes. Multimodal AI models can analyze disparate data sources, including genetic data, electronic health records, and Build private LLM initiatives, to identify patterns and relationships that might elude human researchers. This facilitates the identification of promising drug candidates, accelerating the development of new drugs and ultimately bringing them to the market more efficiently.
2. Automotive Industry
Within the automotive industry, multimodal AI technology has been embraced early on. Companies utilize this technology to improve convenience, safety, and the overall driving experience. In recent years, the automotive sector has made significant progress in integrating multimodal AI systems into HMI (human-machine interface) assistants, driver assistance systems, and driver monitoring systems.
Specifically, modern vehicles’ HMI technology has been notably enhanced by multimodal AI. This technology enables voice and gesture recognition, which makes it easier for drivers to interact with their vehicles. Additionally, driver monitoring systems powered by multimodal AI can effectively detect driver drowsiness, fatigue, and inattention through various modalities, such as eye-tracking, facial recognition, and steering wheel movements. These advancements contribute to increased safety and a more enjoyable driving experience.
3. Human-Computer Interaction
Multimodal AI, a rapidly evolving field in artificial intelligence, holds immense potential to revolutionize the way we interact with computers and technology. By processing inputs from multiple modalities, such as speech, gestures, and facial expressions, multimodal AI systems can enable more intuitive and natural interactions between humans and machines. One of the key strengths of multimodal AI is its ability to understand and respond to complex human communication. By combining information from multiple modalities, multimodal AI systems can gain a deeper understanding of a user’s intent and context.
For example, a multimodal AI system can analyze a user’s speech, gestures, and facial expressions to determine if they are asking a question, making a request, or simply expressing an emotion. This rich understanding of human communication allows multimodal AI systems to provide more relevant and personalized responses. Another advantage of multimodal AI is its potential to enhance the accessibility of technology for people with disabilities. By offering alternative input methods, such as gestures and facial expressions, multimodal AI systems can make it easier for people with limited mobility or speech impairments to interact with computers. This can have a profound impact on their ability to communicate, learn, and work.
4. Weather Forecasting
Multimodal AI is a cutting-edge technology that revolutionizes weather forecasting by integrating and analyzing data from various sources. Its capabilities extend beyond traditional weather stations and numerical weather prediction models. Multimodal AI harnesses the power of satellite imagery, weather sensors, historical data, and even social media feeds to create a comprehensive understanding of atmospheric conditions. Satellite imagery plays a crucial role in multimodal AI weather forecasting. Satellites orbit the Earth, capturing images of cloud formations, sea surface temperatures, and other factors that influence weather patterns. Multimodal AI algorithms analyze these images, identifying features such as cloud types, wind patterns, and moisture levels. By combining this information with data from weather sensors on the ground, multimodal AI can paint a detailed picture of current weather conditions.
5. Language Translation
Multimodal artificial intelligence (AI) systems possess the remarkable ability to translate spoken words from one language to another and back again. However, their capabilities extend far beyond mere linguistic conversion. These systems are equipped to process a multitude of contextual cues, including gestures, facial expressions, and other speech-related factors, to deliver translations that are not only accurate but also nuanced and contextually appropriate. At the heart of these multimodal AI systems lies a sophisticated network of algorithms and machine learning models. These models are trained on vast datasets of multilingual text, audio, and video data, enabling them to learn the intricate relationships between words, sounds, and visual cues.
By leveraging this knowledge, the systems can identify and interpret the various elements that contribute to a speaker’s message, resulting in translations that capture not only the literal meaning but also the emotional and cultural subtext. One key advantage of multimodal AI translation systems is their ability to handle ambiguous or context-dependent expressions. For example, a phrase like “It’s raining cats and dogs” may have a different meaning in different cultures and contexts. The system can analyze the speaker’s tone, facial expression, and gestures to determine whether the phrase is intended to convey a literal description of heavy rainfall or a figurative expression of surprise or frustration.
6. Multimedia Content Creation
Multimodal AI encompasses an innovative approach to content creation by utilizing various input modalities. These modalities can range from text descriptions that provide detailed information, audio recordings that capture ambient sounds or narrations, and visual references such as images or videos. This combination of modalities enables Multimodal AI to understand and interpret content in a comprehensive manner, allowing it to create multimedia content that is both engaging and informative. One of the key advantages of Multimodal AI in content creation is its ability to automate processes. By leveraging deep learning algorithms, Multimodal AI can analyze and synthesize different modalities to generate cohesive content.
This automation capability significantly reduces the time and effort required for content creation, making it a highly efficient solution for businesses and individuals alike. Moreover, Multimodal AI has the ability to produce high-quality content that resonates with audiences. By incorporating multiple modalities, Multimodal AI can capture the essence of a message and convey it in a way that is both visually appealing and emotionally impactful. This makes it an ideal choice for creating content for social media, marketing campaigns, and educational purposes.

Conclusion
Multimodal models represent a significant leap in the evolution of artificial intelligence, enabling the seamless integration of multiple data types such as text, images, and audio to create a more holistic understanding of information. These models connect how humans process visuals, text, audio, and more. These models evaluate and combine data kinds to develop better, more intuitive AI systems. Their healthcare and customer service applications are growing, and the technology is improving.
Whether you are looking to understand how multimodal models work or explore the future of multimodal models, staying informed about these trends is crucial. As multimodal AI becomes more accessible, it opens up endless possibilities for innovation. Whether you’re a developer, business leader, or tech enthusiast, understanding these models is key to staying ahead.
SoluLab an LLM development company has its team of expert to discuss your business queries and come up with innovative solutions. Contact us today to discuss further!
FAQs
1. What is an example of a multimodal model?
OpenAI’s GPT-4 with Vision and Google DeepMind’s Gemini are great examples of multimodal models.
2. Can small businesses use multimodal Models?
Absolutely. With API-based tools and open-source models, even small businesses can tap into multimodal capabilities.
3. What are multimodal foundation models?
Multimodal foundation models are large, pre-trained AI models designed to handle a variety of tasks by leveraging multiple data modalities. These models serve as a base for fine-tuning specific applications across different industries.
4. Are multimodal models accurate?
Yes, when trained well, they can outperform single-modal models by combining insights across data types.
5. How can I start working with multimodal models?
You can explore open-source models like CLIP, BLIP, or FLAVA or use APIs from platforms like OpenAI and Hugging Face.



