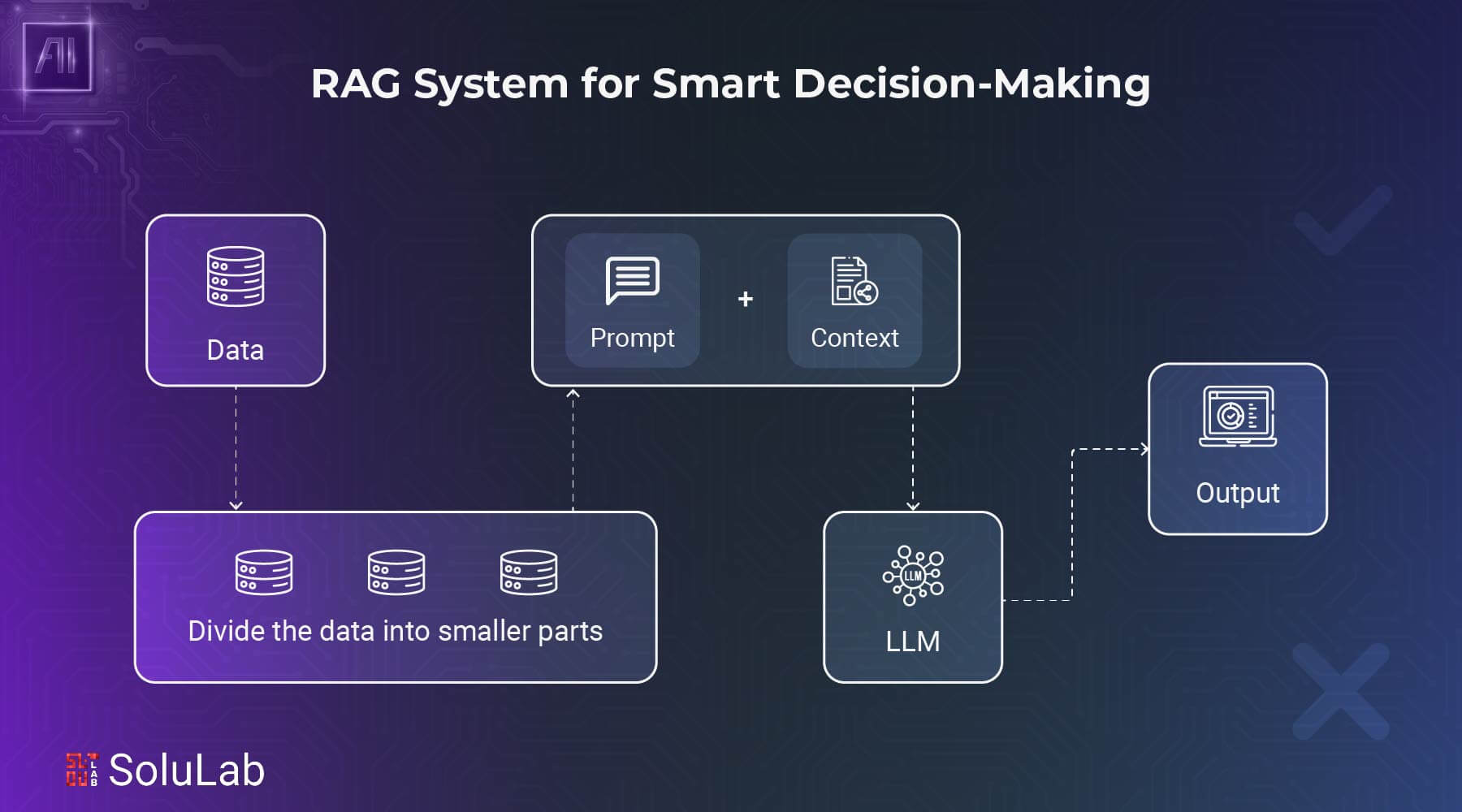
Businesses today deal with vast amounts of data, but turning it into useful insights is a challenge. A Retrieval-Augmented Generation (RAG) system, combined with Agentic AI, helps by retrieving, processing, and delivering real-time insights. This allows businesses to create smart agents that query data, adapt, and extract key information on products, integrations, and operations.
The global Retrieval-Augmented Generation (RAG) market was valued at USD 1,042.7 million in 2023 and is expected to grow at a CAGR of 44.7% from 2024 to 2030. This rapid growth is driven by advancements in natural language processing (NLP) and the rising demand for intelligent AI systems.
By integrating RAG with Agentic AI, companies can improve decision-making and transform scattered data into valuable intelligence. This blog will guide you through building a RAG pipeline with Agentic AI, including technical insights and code examples.
What is a RAG System?
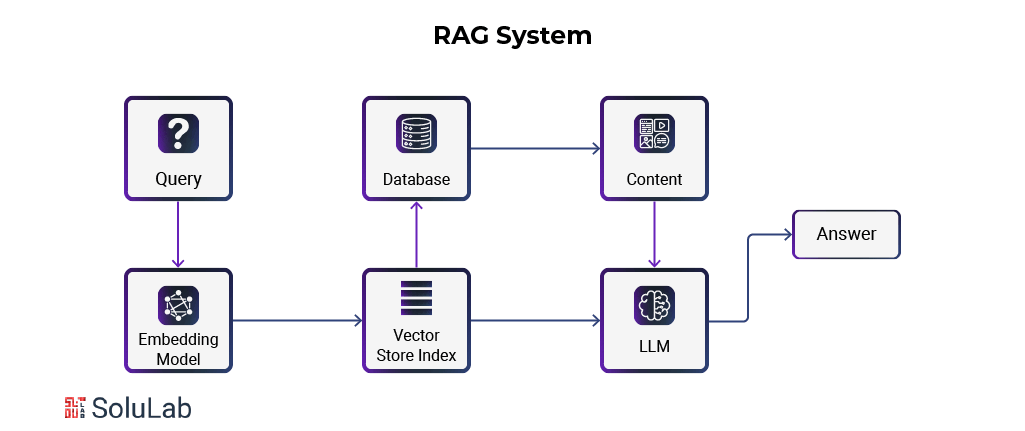
RAG, or retrieval-augmented generation, is a procedure that improves the relevance of large language models’ outputs for end users.
The ability of large language models (LLMs) to produce content has advanced significantly in recent years. However, several executives have been let down by these models, which they believed would boost productivity and corporate efficiency. The significant buzz around generative artificial intelligence (gen AI) has not yet been fulfilled by off-the-shelf solutions.
For starters, LLMs are only taught the data that the providers that create them have access to. This may reduce their usefulness in settings that require a greater variety of more complex, enterprise-specific information.
How Does RAG Work?
The agentic RAG process involves intake and retrieval. Imagine a big library with millions of volumes to grasp these ideas.
1. The initial “ingestion” phase is like stocking the shelves and building an index, which helps librarians find any book in the collection. This procedure generates dense vector representations, or “embeddings” (for more, see sidebar, “What are embeddings?”), for each book, chapter, or paragraph.
2. When the library is stocked and indexed, “retrieval” begins. The librarian searches the index for appropriate books when a user asks a question. Selected books are scanned for relevant content, which is retrieved and synthesized into a compact output.
3. The librarian uses the original question to investigate and choose the most relevant and correct material. This may require summarizing significant ideas from many sources, quoting authoritative works, or creating new content based on library discoveries.
4. These ingestion and retrieval phases allow RAG to produce extremely specific outputs that typical LLMs cannot. The librarian uses the stocked library and index to pick and synthesize content to answer a query, providing a more relevant and helpful answer.
Data Extraction Using BFS and Scraping the Data
Data collection is the initial stage in developing an effective RAG system for company insight. Data from varied web sources must be efficiently scraped and organized. Breadth-First Search helps find and collect relevant pages. BFS recursively finds links from a primary page. This lets us collect all relevant pages without overloading the system.
This section shows how to use BFS to extract links from a website and scrape its content. BFS helps us navigate websites, collect data, and produce a meaningful dataset for RAG pipeline processing.
1. Step 1: Link Extraction Using BFS
We must first gather all essential links from a website. BFS lets us examine the homepage links and follow links on other pages recursively up to a certain depth. We capture all important company data, such as product features, integrations, and other details, using this manner.
The code below extracts links from a beginning URL using BFS. After retrieving the primary page, it extracts all links ( tags with href attributes) and follows them to subsequent pages, widening the search based on a depth limit.
Step 2: Scraping Data from Extracted Links
Scraping the text from these pages follows BFS extraction of pertinent links. We’ll search for product features, integrations, and other pertinent data to construct an organized RAG dataset.
In this phase, we loop through the retrieved links and scrape page titles and primary content. This code can be modified to scrape product characteristics, pricing, and FAQs.
Related: Retrieval-Augmented Generation (RAG) vs LLM Fine-Tuning
Automating Information Extraction with AI Agent
In the last part, we discussed how to use a breadth-first search (BFS) method to scrape links and gather unfiltered web information. We require a reliable system for classifying and deriving useful insights from the essential data once it has been scrapped. Here’s where agentic AI comes in: it automatically organizes the material into sections that make sense by processing the scraped data.
This section focuses on the process by which Agentic AI retrieves pertinent product data from the data that has been scraped.
1. Loading Scraped Data
In this process, loading the raw content that has been scraped into our system is the initial step. The scraped data is saved in JSON format, as we previously saw, and each entry contains a URL and related material. For the AI to process this data, we must make sure it is in an appropriate format.
Here, we use Python’s built-in JSON module to load the complete dataset into memory. The source URL and a text_content field with the raw scraped text are included in every dataset entry. In the next phases, we will process this content.
2. Extracting Raw Text Content
The relevant text content for each element is then extracted by iterating through the dataset. This guarantees that we only deal with legitimate entries that include the required information. To preserve the process’s integrity, entries that are deemed invalid or incomplete are omitted.
The raw text content that we will now provide to the AI model for additional processing is included in the input_text variable. Before processing each entry, we must ensure the required keys are present.
3. Sending Data to the AI Agent for Processing
We transfer the raw content to the AI agent model for structured extraction after it has been extracted. Using preset prompts, we communicate with the Groq API to seek structured insights. After processing the content, the AI model provides well-structured information covering important topics including product features, integrations, and troubleshooting techniques.

4. Processing and Collecting Results
The AI model returns structured information in chunks after processing the content. To ensure that no data is lost and that the final output is comprehensive, we gather and concatenate these pieces to produce a complete set of findings.
This piece of code creates a complete, organized set of insights by concatenating the material from each chunk to the pm_points variable. Stakeholders can readily consume or utilize the format in which it extracts these insights for additional study. The output screenshot of the original code is shown below, with crucial data obscured to preserve integrity.
5. Error Handling and Maintaining Data Integrity
There is always a chance that errors, such as missing content or network problems, will occur during processing. We guarantee that the procedure proceeds without hiccups for every legitimate entry by utilizing error-handling techniques.
To guarantee that the system keeps processing other entries, this try-except block detects and logs any failures. The system flags an entry for review if it raises a problem without stopping the process as a whole.
6. Saving the Processed Data
The last step is to save the data annotation for later use once the AI has processed the content and produced structured insights. To ensure that each item has its unique processing information saved for future analysis, we write the structured findings back into a JSON file.
This code effectively retains the processed data and makes it accessible at a later time. It makes it easy to retrieve and analyze the gathered data by saving each entry with its unique structured points.
Retrieval-Augmented Generation Pipeline Implementation
In the previous section, we extracted data from web pages and converted it into structured forms like JSON. We also extracted and cleaned essential data to create a dataset ready for analysis.
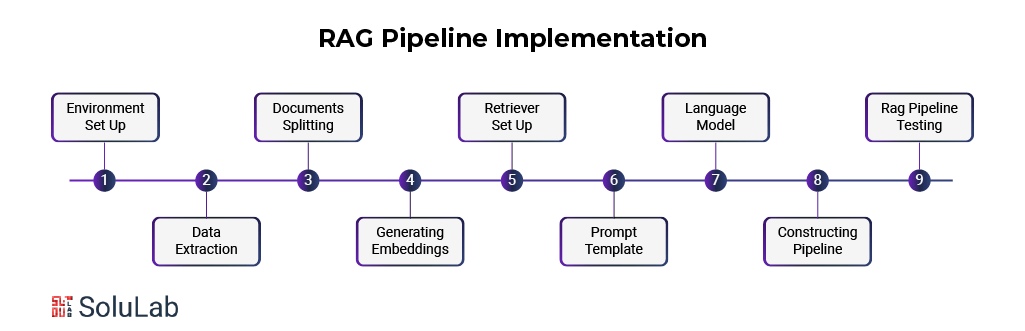
1. Setting Up The Environment
These packages are essential for LangChain document processing, vector processing, and OpenAI model integration. Langchain is the framework for language model pipelines, whereas jq is a lightweight JSON processor. long-chain-chroma provides Chroma-based vector storage for document embeddings, while long-chain-open integrates OpenAI models like GPT.
We also construct text embeddings with pre-trained transformer models using sentence transformers for efficient document handling and retrieval.
2. Loading The Extracted Data
JSON Loader will load the structured data retrieved and processed in the preceding phase. This structured JSON data from websites may have had key-value pairs relevant to specific subjects or inquiries. This stage loads extracted data (such as product capabilities, integrations, and features) for processing.
3. Splitting The Documents Into Smaller Chunks
After obtaining the raw data, we utilize the RecursiveCharacterTextSplitter to fragment the document. This prevents any chunk from exceeding the language model token limit.
The RecursiveCharacterTextSplitter breaks apart a document to maintain chunk overlaps for context. Chunking_size controls chunk size, whereas chunk_overlap preserves crucial information between chunks. Add_start_index also maintains document order by including an index to track where each chunk started in the original document.
4. Generating Embeddings For Document Chunks
Now, we use SentenceTransformer to embed each chunk of text. These embeddings represent text meaning in a high-dimensional vector space for later document searching and retrieval.
SentenceTransformer creates text chunk embeddings as dense vector representations of semantic information. While embed_query generates embeddings for user queries, embed_documents processes numerous documents and returns their embeddings. Chroma, a vector store, stores these embeddings and allows similarity-based retrieval for fast and accurate document or query matching.
5. Setting Up The Retriever
Now, configure the retriever. This component finds the most appropriate text depending on a user query. The top-k documents most similar to the query are returned. The retriever finds appropriate vector store chunks using similarity search. The argument k=6 returns the top 6 query-relevant chunks.
6. Creating The Prompt Template
We then develop a prompt template to format language model input. This template includes the context (retrieved chunks) and the user’s query, encouraging the model to answer only from the context.
The ChatPromptTemplate structures model input to show the necessity for context-based answers; {context} will be replaced with relevant text, and {question} with the user’s query.
7. Setting Up The Language Model
OpenAI GPT model initialization occurs here. The retriever’s structured context will inform this model’s answers.
The ChatOpenAI model processes the prompt and responds after initialization.
We employ “GPT-4o-mini” for efficient processing, although larger models can handle more difficult tasks.
8. Constructing The Rag Pipeline
Here, we combine retriever, prompt, and LLM into an RAG pipeline. This pipeline retrieves context, passes it through the model, and returns a response.
imported langchain_core.output_parsers Import StrOutputParser from langchain_core.runnables. RunnablePassthrough. RunnablePassthrough passes queries directly to prompts. StrOutputParser cleans and formats model output into strings.
9. Testing The Rag Pipeline
We test the pipeline with user queries last. The system obtains document chunks for each query, runs the language model, and responds.
For each inquiry, the system invokes the pipeline and prints the result. The model answers each question using the retrieved context.
Read Also: Agentic AI Frameworks
Deployment and Scaling
After building the firm intelligence system, launch and scale it for production. You can deploy the system on AWS or GCP for flexibility and scalability or on-premise for data privacy. Build a simple API or UI to make the platform easier to use and retrieve insights. Efficiently scaling is crucial as datasets and query demands grow.
Distributed vector stores and retrieval optimization help keep the pipeline responsive and quick even under heavy usage. The agentic platform can handle large-scale operations with the correct infrastructure and optimization methodologies, providing real-time insights and keeping company intelligence competitive.
Applications of RAG Across Industries
Here are some applications of RAg across industries:
1. Customer Intent Resolver In Retail
This is among the most widely used RAG system implementations in the retail industry. To assist in resolving any problems, the RAG agent is well-versed in all product details, manuals, frequently asked questions, customer reviews, and support tickets.
It also keeps refining its responses by learning from every client engagement. This improves the whole purchasing experience and fosters customer trust by guaranteeing that customers receive accurate and consistent responses from all of their interactions.
2. Clinical Evidence Synthesis Engine In Healthcare
RAG models can be applied to AI in the healthcare industry to help clinicians identify the most effective therapies for individual patient circumstances. It facilitates decision-making by relating symptoms to possible therapies and pertinent studies. Crucially, it maintains all required data while scrupulously following privacy laws, guaranteeing patient privacy at all times.
3. Risk Pattern Recognition System In Insurance
In this instance, RAG learns from the data to improve decision-making by examining trends from thousands of previous policies and claims. In addition to spotting dangerous trends that human assessors might miss, it aids in ensuring constant reviews of insurance plans. Insurance professionals can make more dependable and knowledgeable selections by utilizing its insights.
4. Educational Personalization Assistant
An intelligent tutoring system that serves as a personalized educational companion is an example of a RAG in education. It can modify course material to fit the learning preferences, speed, and comprehension level of each learner. It’s similar to having a committed tutor who keeps track of every conversation and modifies their teaching strategies in response to students’ development.
5. Real Estate Market Intelligence System
An all-inclusive property assessment system that serves as a knowledgeable real estate tokenization advisor by combining market trends, historical data, and property-specific details to produce in-depth analyses and assessments.
Which Areas of the Business Stand to Benefit from RAG Systems?
RAG has broad applications in customer service, marketing, finance, and knowledge management. RAG integration into current systems can improve customer satisfaction, decrease costs, and boost performance by producing more accurate outputs than off-the-shelf LLMs. Here are some RAG applications:
- Chatbot for Enterprise Knowledge Management: RAG may extract relevant information from across the enterprise, synthesize it, and deliver actionable insights to employees searching the intranet or other internal knowledge sources.
- Customer Service Chatbots: When a consumer visits a company’s website or mobile app to ask about a product or service, the RAG system chatbot development can extract relevant information from corporate policies, customer account data, and other sources to deliver more accurate and useful responses.
- Drafting Assistance: The RAG system retrieves company-specific data from enterprise data sources like databases, spreadsheets, and other systems and prepopulates sections of a report or document when an employee starts writing it. This result can assist the employee in preparing the document faster and better.

Conclusion
Designing a Retrieval-Augmented Generation (RAG) system for smarter decision-making requires a structured approach that balances efficient data retrieval and intelligent content generation. By integrating a retrieval mechanism with a powerful language model, businesses can enhance their decision-making capabilities with precise, contextually relevant insights. A Retrieval-Augmented Generation (RAG) system helps collect, organize, and retrieve key information, allowing businesses to get useful insights in real-time.
This AI-powered tool supports smart decision-making, adapts to growing data needs, and handles complex queries accurately. The right setup becomes a vital part of business operations, helping companies stay competitive and innovate.
SoluLab is an RAG app development company that has a team of experts who can help you in your business. Contact us today to discuss this further!
FAQs
1. What are the key components of a RAG system?
A RAG system includes data retrieval mechanisms, AI-powered processing, intelligent querying, and a user-friendly interface. These components work together to provide structured, insightful, and actionable business intelligence.
2. How scalable is a RAG system?
A RAG app development system is highly scalable, handling increasing data loads and complex queries as a business grows. It can integrate with cloud solutions to ensure flexibility and efficiency.
3. What are the challenges of implementing a RAG system?
Challenges include data quality issues, integration complexities, and maintaining accuracy in responses. However, with the right infrastructure and AI models, these challenges can be minimized.
4. What industries can benefit from a RAG system?
Industries like finance, healthcare, e-commerce, and logistics benefit from RAG systems. These systems help extract insights, automate responses, and improve operational efficiency across sectors handling large datasets.
5. What are the challenges of implementing a RAG system?
Challenges include data quality issues, integration complexities, and maintaining accuracy in responses. However, with the right infrastructure and AI models, these challenges can be minimized.


