Machine learning algorithms can organize and comprehend human language with the help of natural language processing (NLP). Machines can now collect speech and text and determine the main meaning they should react to with NLP. NLP application has significant challenges due to human language’s complexity and ongoing continual growth. One of the numerous components that make up NLP’s operation is tokenization.
One of the initial steps in any natural language processing is tokenization. Simply dividing the original text into discrete word or sentence segments known as tokens, is the process of tokenization. It is referred to as “word tokenization” if the text is divided into words and sentence tokenization if it is divided into sentences. Sentence tokenization uses characters like periods, exclamation points, and newline characters, while word tokenization typically uses “space”. Depending on the work at hand, we must select the best approach. A few characters, such as spaces and punctuation, are disregarded throughout the tokenization process and will not appear in the final collection of tokens. This article will guide you about what is tokenization in NLP, what are its types and why is it important.
What is Natural Language Processing?

The field of artificial intelligence known as Natural Language Processing (NLP) is devoted to creating computer algorithms that enable machines to read, comprehend, and produce language. This covers spoken and written language to enable computers to understand and exchange language like that of humans. To accomplish this, NLP models examine the material and purpose of communications and decipher their underlying meaning by combining machine-learning techniques with pre-established rules.
Natural language processing bridges the gap between human and computer languages by utilizing both linguistics and mathematics. Natural language typically manifests as either speech or text. These organic channels of communication are converted into machine-understandable data using natural language processing methods.
What is Tokenization in NLP and Why Do You Need It?
Tokenization in NLP is the process of dividing a stream of text into more manageable, smaller pieces known as tokens in natural language processing. Words, sentences, letters, and other significant components can all be considered tokens. Since tokenization enables the system to process and access the text in more manageable, structured chunks, it is an essential stage in many NLP activities. As it makes it possible to do further NLP tasks like text, categorization, praising, translation, and part-of-speech tagging, tokenization is essential. It becomes significantly more difficult to comprehend the meaning and structure of language when tokenization is not done correctly.
Need For Tokenization
The initial stage of any NLP pipeline is tokenization, it significantly impacts the rest of your pipeline. Asset Tokenization is the division of unstructured data and natural language text into discrete pieces. It is possible to use a document’s token occurrences as a vector representation of that document.
This instantly transforms an unstructured text document into a machine-learning-ready numerical data structure. A computer can also use them directly to initiate helpful reactions and actions. Alternatively, they could be employed as features that initiate more intricate choices or actions in a machine-learning pipeline.

Which Should You Use in NLP?
Word tokenization is a commonly used technique in Natural Language Processing or NLP. It takes a text stream and splits it into single words, which are the smallest meaningful units in many languages. Words carry the most semantic content, making this approach key for text analysis, understanding, and generation. It works well for tasks that need word-level detail to give the correct answer, like content creation, text classification, and sentiment analysis. In this context, words are more important and separate units for NLP models. Additionally, word tokenization allows for effective computing and helps manage different forms of language. Why tokenize words? The reasons for word tokenization are effective for content generation.
- Readability: There are some conventional distinctions between words and phrases in most of the world’s languages.
- Coarseness: It provides only the information necessary for tasks, such as correcting grammar, identifying sentiment and keyword extraction, and so on.
- Widely used: Most of the content-based NLP applications use it including the summary writing assistants.
Tokenization example in NLP, Let’s break down the use case using some examples below:
Blog Generation
This would be inputted: Tokenization is therefore a crucial step when carrying out analysis in the field of NLP.
It is word-tokenized as follows:
[“Tokenization”, “is”, “a”, “important”, “step”, “in”, “NLP”].
At this level of tokenization, there are rich terms that the algorithms can identify in what we have highlighted as; Tokenization and NLP.
Sentiment Analysis

This sentence: “I love this tool!”
[this, love, absolutely, I, and tool].
This enables sentiment score systems in the ability to look for words such as ‘love.’
Many of Google’s natural language processing models like BERT employ word and subword tokenization as the first step before text preprocessing for utilization of the texts in tasks such as search or content generation.
Types of Tokenization in NLP
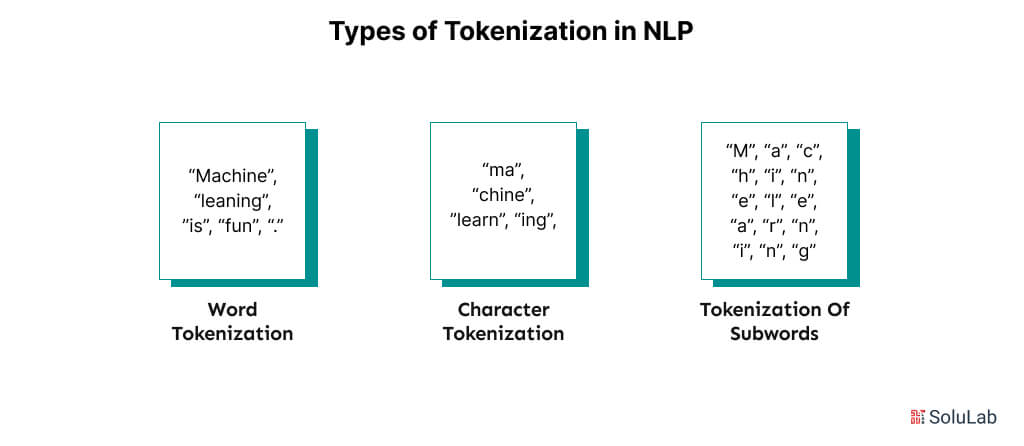
There are several ways tokenization can be done such as real-estate tokenization, which will later make use of natural language processing stages significantly. Here are the main types of Tokenization in NLP:
-
Word Tokenization
The most common tokenization technique in NLP is the word tokenization. Using characters like “, ” or “;” segments the data at the individual words when there are natural interruptions, such as speech pauses or text spaces. This is the most obvious technique in terms of breaking voices or texts into their parts, yet this method has many drawbacks. Word tokenization has a hard time separating unclear or OOV words. This is often resolved by replacing an easy token that specifies a word that is out of vocabulary with unknown terms. The accuracy of word tokenization is determined by the vocabulary used to train it. To be as accurate as possible and to result in maximum efficiency, loading words must be balanced for these models. Even though integrating all the words from a dictionary may enhance an NLP model’s accuracy, this is not always the best method. This is particularly valid in cases where models are being trained for specialized applications.
-
Character Tokenization
To solve some of the problems associated with word tokenization, character tokenization was developed. Instead of dividing text into words, it breaks the text into characters wholly. This makes it possible for the tokenization procedure to preserve OOV word information that word tokenization is unable to. Whereas in the case of word tokenization, vocabulary size is a problem due to its massive size, the “Vocabulary” in character tokenization is relatively small and determined by the number of characters required by a language. Thus a character tokenization vocabulary for English would contain something like 26 characters.
Character tokenization overcomes OOV issues but has its disadvantages. The output’s length is greatly increased as even the simplest sentences break up into characters rather than words. Our earlier example, “What restaurants are nearby,” is split into four tokens using word tokenization. Character tokenization splits this into 24 tokens by increasing the number of available tokens by a factor of 6.
-
Tokenization of Subwords
Like word tokenization, subword tokenization relies on specific linguistic rules to break down individual words further. One of the primary tools they use is breaking off affixes. Since prefixes, suffixes, and infixes all change the inherent meaning of a word, they can also help programs understand what a word does. This is particularly useful with dictionary words since determining an affix can give the software an idea of how unknown words. The subword model will find these subwords, and it will then break apart words that have these subwords. For example, the question “What is the tallest building?” would turn into the separate pieces “what,” “is,” “the,” “tall,” “est,” and “ing.”
Why is Tokenization Important?
Examples of computer-mediated tools include; emails, online posts, and news articles. These texts do not come like preprogrammed instructions that the computers can easily download what is supposed to be conveyed. Tokenization Platform Development Company addresses this shortfall by providing tokenization services which subdividing the text into portions referred to as tokens. Thus, the unstructured material receives a structured format here in the form of a tokenized format, which would excite more processing and analysis.
Tokenization is mainly the overall steps to convert the input text into the form the ML algorithms can work with. Employing these numerals, people can train the model for several operations such as sentiment analysis, language generation, and classification.
Tokens can also be considered figures in features in a pipeline excluding the numerical portrayal of text. They are those that would result in more complex decisions or actions and also encompass extensive linguistic information. For instance, in text classification, the outcome of the prediction of some of the classes could heavily rely on whether or not any token is available. Therefore, tokenization is very important if you require useful features that help simple machine-learning models.
In general, words in natural languages have multiple meanings depending on the situational context of the word; that is, they are inherently ambiguous. Tokenization is useful to reduce the possible ambiguation of one or another word at the time when it is necessary to analyze it about its other tokens being positioned near it. This approach offers a deeper and more refined interpretation of the type and, all the same, enhances the precision of future steps.
Related: Tokenization of Real-World Asset
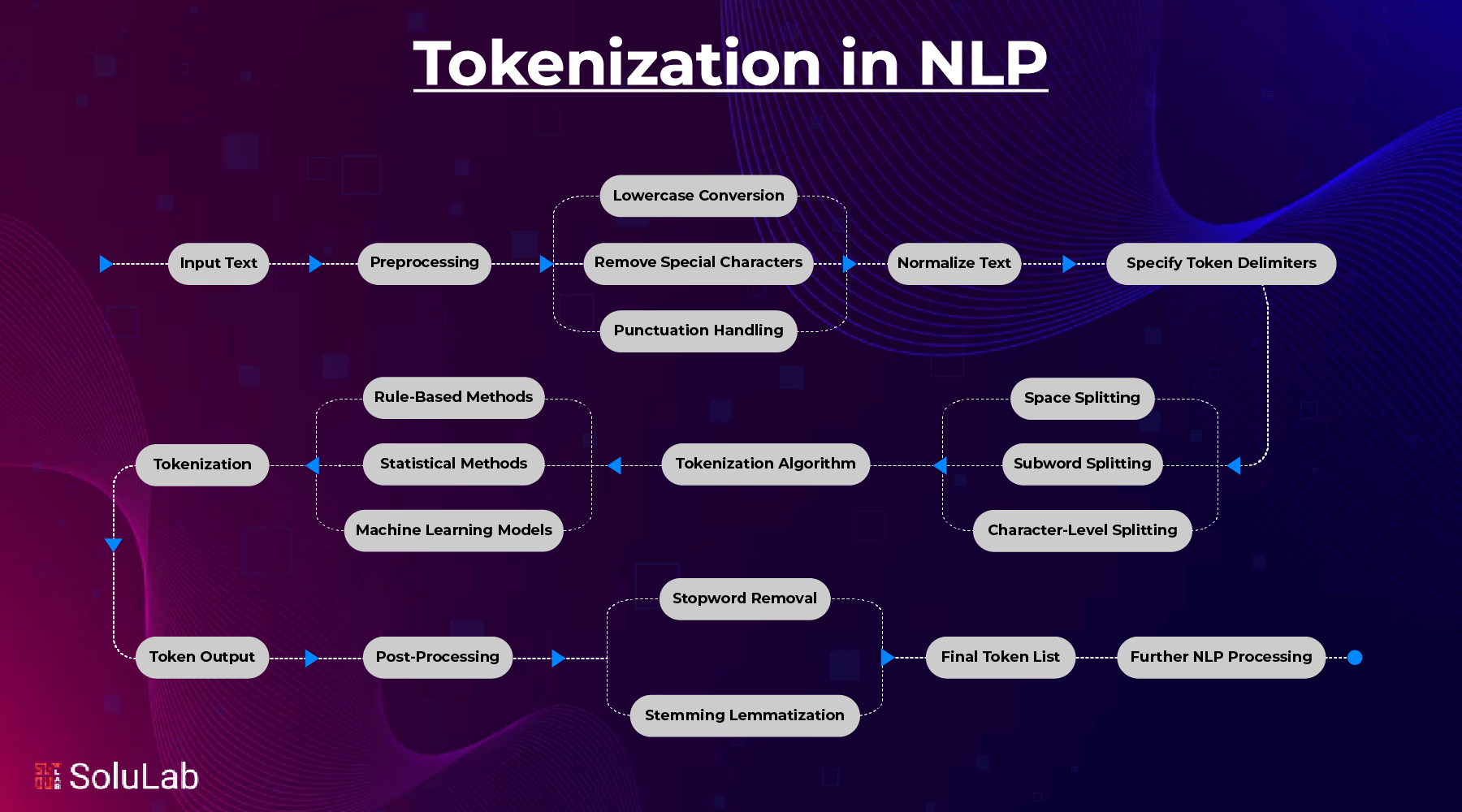
How Does Tokenization Work in Natural Language Processing?
You should know that tokenization is one of the basic levels in the tokenization process in NLP. Depending on the string’s density of analysis, tokens could be words, subwords, characters, or sentences. The concept used in the text segmentation makes enhanced computation for a better understanding of the NLP proposed model possible. Here is the breakdown of how tokenization works in NLP:
1. Input of Text
A procedure begins with an input of raw texts. This can be one particular paragraph, a given sentence of the whole document being processed. For instance: There are many different sub-topics in NLP however it is important here to note that ‘‘NLP tasks require tokenization.
2. Processing
Text is often preprocessed to clean and normalize data before tokenization in a way to maintain the order Lowercase predictably transforms a set of text in lowercase letters (for example, “Tokenization” becomes “tokenization”).
Specific Characters: These are ‘emoticons’ such as @, #, &, etc.
Managing Punctuation: Decides if punctuation should not be considered as tokens or stay as individual tokens.
3. Specifying Token Delimiters
Tokenization develops patterns or rules by which the starting and finishing points of a token are to be identified. In particular English and the related language, word tokenization involves splitting text through the use of space. Tokenization is very important, for example, there is a splitting into [Tokenization, is, important]. Subword tokenization splits words into even smaller parts with BPE often or always used as a subword technology. Such as Unhappiness – [un, happiness]. Character tokenization treats each character as a token: [ “N”, “L”, “P” ] → “NLP”. They include the identification of a period or other special character to mark some kind of cognitive separation between one paragraph and another known as sentence tokenization.
4 Tokenization Algorithm
Use different algorithms for various tokenization techniques based on necessity:
Rule-Based Tokenization: It uses prespecified rules such as spaces or punctuation marks.
Statistical Methods: It uses frequency or probability-based models that decide the token boundaries for languages like Chinese or Japanese.
Machine Learning Models: Some systems learn to recognize the token boundary when applied to difficult languages or special tasks.
5. Output Tokens
The result of tokenization is a sequence of tokens that may be processed further. For instance:
- Word tokenization of: “I love NLP!”
- Output: [“I”, “love”, “NLP”, “!”].
- Subword tokenization for: “unpredictable”
- Output: [“un”, “predict”, “able”].
6. The Algorithm for Tokenization
Depending on the requirements, multiple algorithms or tokenization methods are used:
- Rule-Based Tokenization: It operates based on pre-defined rules; either punctuation or space.
- Statistical Methods: Token boundaries are determined based on frequency or probability-based models, especially when it is different languages like Chinese or Japanese that don’t have spaces.
- Machine Learning Models: Some systems train models to learn token boundaries for particular tasks or hard languages.
7. Tokens for Output
A list of tokens that can be used for further processing is what tokenization produces as output. For example:
Tokenizing the sentence “I love NLP!”
[ “I”, “love”, “NLP”, “!” End
Tokenizing the subword “unpredictable”
[ “un”, “predict”, “able” ] End
8. After-processing
After tokenization, the tokens can then be optionally processed for some specific needs:
Removes common but non-informative words such as “is”, “the”, etc with stopword removal.
Words are reduced to their base or root forms through either stemming or lemmatization (“running” → “run”).
9. Libraries and Tools
This process is built into many libraries.
- NLTK: Basic word and sentence tokenizers
- SpaCy: Fast tokenizers for specific languages.
- Hugging Face Transformers: Focused more on subword tokenization for advanced models of NL.
This process will make it possible for NLP systems to analyze and understand language fluidly using structured tokens broken down from the text as the foundation for these activities such as sentiment analysis, translation, and text generation.
Read Also: NLP in Customer Service
Challenges and Limitations of Tokenization in NLP
Most of the time, this process is used on French or English corpora where punctuation marks or white space is used as demarcations for sentences. Other languages like Chinese, Japanese, Korean, Thai, Hindi, Urdu, Tamil, and others had to unfortunately be left out for this reason. It is a call for a universal tool in tokenization that combines all languages as Arabic is a morphologically complex language, and so too, the tokenization of Arabic texts. For instance, one word in Arabic “عقد” eaqad may have up to six tokens. One Arabic word could represent six different English words.
These difficulties expose how vital it is that a uniform tool for tokenization could be applied to a very large variety of languages and linguistic frameworks. Such a tool would provide integration of statistical models, machine learning, contextual analysis, and the rules and algorithms specific to certain families of language. For example, such a decomposition of Arabic words to their basic components, morphological prefixes, and suffixes, may be beneficial, while dictionary-based approaches, as well as context-aware models, might be applied to define word boundaries for Chinese or Thai. Solving these challenges is essentially important to maintain inclusiveness in cross-lingual applications by making NLP accurate and accessible across languages.

How Does SoluLab Enhance Transaction Efficiency in Tokenization for Business?
Blockchain technology, which allows companies to bring in Blockchain Applications, assets, currency, and data tokenization into efficiency and scalability, and NLP break texts down into meaningful components, both place reliance on the revolutionary concept of tokenization. SoluLab takes tokenization to the next level by making it easy for companies to better secure information, smooth out processes around transactions, and present flawless user experiences. SoluLab creatively resolves problems of operational complexity, scalability, and transparency using blockchain technology, ensuring quicker and more economical processes.
Token World aimed to make a launchpad for a cryptocurrency that would link investors to blockchain companies. The idea of this platform ensured high security while developing the blockchain ecosystem, yet it had problems with navigation, integrity of data, and scalability. In collaboration with SoluLab, Token World acquired a one-of-a-kind solution based on blockchain, which represents cutting-edge security that ensures a hassle-free process both in the listing of projects and the interaction of investors.
Let SoluLab turn your idea into reality, with customized blockchain solutions that enhance scalability, security, and efficiency. To learn how we can help you and your business succeed, reach out to us today!
FAQs
1. What is the purpose of tokenization?
Tokenization aims to safeguard private information while maintaining its commercial value. This is not the same as encryption, which alters and stores private information in ways that prevent its use for commercial objectives.
2. What does types vs tokens mean in NLP?
An instance of a character sequence in a certain document that is put together as a helpful conceptual unit for processing is called a token. The class of all tokens with exactly similar character sequences is called a type.
3. What is the purpose of NLTK?
The natural language toolkit, or simply NLTK is a collection of Python programming language modules and applications for statistical and symbolic NLP of English. Semantic reasoning, stemming, tagging, classification, and parsing are all supported.
4. What are the advantages of tokenization?
As many blockchains are inherently public, one of the main advantages of tokenization in NLP is that it makes it possible to track and audit all of this information openly. Depending on the asset’s smart contract logic, tokenization allows users to view an ownership record in addition to interest or dividend returns.
5. What are tokens in NLP?
By dividing human language into small portions tokens are the fundamental building elements of language. Tokenization also aids in comprehending and processing these tokens.


