You need to know how to train an AI model, which is simply making sure it learns the appropriate patterns from the correct data if you want it to make reliable and accurate predictions. Businesses are putting more and more trust in AI for sorting through the massive amounts of data that will be created, with the world’s data volume expected to surpass 181 zettabytes by 2025. A new study estimates that artificial intelligence may add $15.7 trillion to the global economy by 2030, more than China and India produce together.
AI models that have been properly trained may automate processes, provide customized suggestions, and uncover insights that humans would not be able to discover. However, models that have been trained poorly or on biased datasets cause more issues than they fix. You may create dependable AI systems by adopting best practices in model training, understanding how to train an AI model, and being aware of the obstacles to expect.
In this blog, we will cover how AI models learn, the key steps of the AI model training process, common challenges like overfitting, and best practices to optimize model performance for real-world applications.
What is AI Model Training?
Fundamentally, an AI model consists of a collection of carefully chosen algorithms as well as the data that is needed to train those algorithms to provide the most precise predictions. The two phrases may overlap in certain instances since a basic model simply employs one method; yet, the model itself is the result of training.
An algorithm may be thought of mathematically as an equation with unknown coefficients. When the chosen algorithms analyze data sets to identify the best-fitting coefficient values, a model for predictions is produced. This process—feeding the algorithm data, analyzing the outcomes, and adjusting the model output to improve accuracy and efficacy—is referred to as “AI model training.” Algorithms need enormous volumes of data that include the whole spectrum of incoming input in order to do this.
Surprises, inconsistencies, outliers, and patterns that don’t seem to make sense at the first look of these and more must be handled regularly by algorithms on all incoming data sets. The capacity to identify patterns, comprehend context, and make wise judgments is the process that forms the basis of learning. When an AI model is sufficiently trained, its collection of algorithms will function as a mathematical predictor for a particular scenario, including tolerances for unforeseen events while optimizing predictability.
The effectiveness of the iterative process of training AI models depends on the caliber and comprehensiveness of the input as well as the trainers’ capacity to recognize and correct any flaws. While certain low-code/no-code settings allow business users to participate, data scientists typically manage the training process. Actually, it’s like teaching a child a new skill—processing, watching, giving feedback, and then improving. The objective of AI model training is to balance the numerous potential variables, outliers, and difficulties in data while developing a mathematical model that reliably produces an output. Parenting gives a similar, but even messier, experience when you think about it.
Think about how kids pick up a skill. For instance, suppose you wish to teach a baby the distinction between cats and dogs. First, there are simple images and words of encouragement. Following that, further characteristics are presented, including specifics like typical sizes, meows vs barks, and behavioral tendencies. To help your child in learning, you might focus more on a certain area based on what the child may be having trouble with. The child should be able to recognize a wide variety of dogs and cats at the end of this procedure, including both typical home pets and wilder animals.
The Importance of AI Models in Business
The majority of businesses now benefit from AI agents in the way they work via apps that create analytics, identify data outliers, or employ text recognition and natural language processing. Imagine transcribing paper receipts and documents into data records, for instance. However, many businesses are aiming to create and train an AI model to answer a particular, critical need. The development process may reveal deeper levels of advantages, ranging from short-term value, like quicker procedures, to long-term gains, such as discovering previously unknown insights or even establishing a new product or service.
The way organizations expand is one of the primary reasons to invest in AI-capable infrastructure. Simply said, data exists everywhere. With so much data streaming in from all sides, fresh insights may be developed for almost every aspect of a business, particularly internal operations and the effectiveness of sales and marketing teams. With that in mind, good training and smart applications enable AI to bring commercial value in almost any scenario.
To evaluate how a business might train AI for optimal value, the first step is to define inputs and what constitutes a sound choice. For example, think of the manufacturing supply chain. Once all necessary data is accessible, a properly trained adaptive AI system can calculate shipping costs, anticipate delivery timeframes and quality/defect rates, propose pricing adjustments depending on market circumstances, and do a variety of other functions. The combination of high incoming data volumes and the requirement for data-driven choices makes supply chains ideal for AI issue resolution. In contrast, if soft skills are still a major focus, AI may give useful information but is not likely to create an innovative transformation. An example is a manager’s evaluation of employee performance during yearly reviews. In this situation, AI may make it simpler to collect measurements, but it cannot replace evaluations done via human-to-human interactions.
To make the most of an AI investment, businesses should consider the following:
- What difficulties do we have to solve?
- Are there any reliable data sources that can help us tackle these problems?
- Do we have the necessary infrastructure to facilitate processing and link key data sources?
- Establishing such characteristics allows firms to identify the business sectors most likely to benefit from AI and then make efforts to make them a reality.

Process of Training an AI Model
Although there are unique obstacles and needs for every project, the overall procedure for training AI models is consistent.
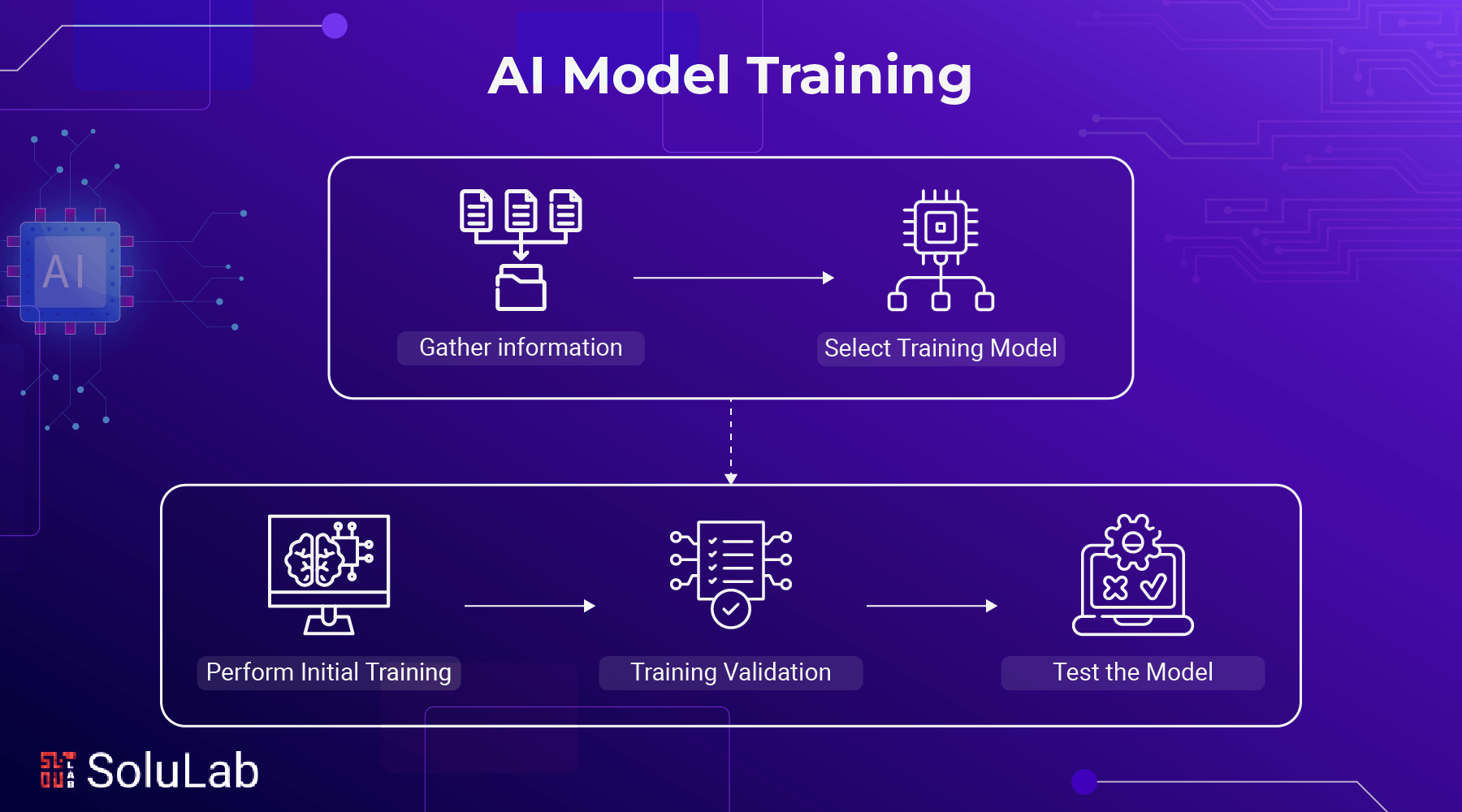
A general outline for the AI model training process consists of these five stages.
- Gather the information: First and foremost in training an AI model effectively is high-quality data that reliably and precisely depicts genuine and real-world scenarios. It is essential for the findings to have any value. Project teams need to make sure they’re using the correct data sources, set up systems for both human and automated data collecting, and implement cleaning and transformation procedures if they want to succeed.
- Select a Training Model: You must choose a training model. If data curation lays the framework for the endeavor, model selection constructs the mechanism. Project specifications and objectives, architecture, and model algorithm selection are all factors to consider while making this choice. These considerations need to be balanced with more pragmatic aspects like computation needs, deadlines, prices, and complexity, as various training models demand varying quantities of resources.
- Perform Initial Training: Training an AI model begins with the fundamentals, much as teaching a youngster to distinguish between a cat and a dog. If the data collection is too large, the method is too complicated, or the model is of the incorrect kind, the system may end up processing data without learning or improving. While initially training, data scientists should aim for outcomes within predicted boundaries and avoid making errors that destroy the system. Models may progress in guaranteed, incremental increments when they are trained without pushing themselves too much.
- Training Validation: After the model successfully completes the first training phase, it consistently produces the predicted outcomes across important criteria. The next step is training validation. In this step, specialists aim to properly test the model in order to uncover algorithmic flaws, surprises, or difficulties. Typically more extensive and sophisticated than the training data sets, this step makes use of a distinct collection of data sets from the first phase. Data scientists assess the model’s efficacy as they iteratively process these datasets. Although the precision of the final product is paramount, the process is of equal or greater importance. Precision (the proportion of right predictions) and recall (the proportion of right class identification) are process priorities. It is possible to use a metric value to evaluate the outcomes in some instances.
- Test the Model: To evaluate the model, first utilize curated and fit-for-purpose data sets to verify it. Then, assess its performance and accuracy using actual data. This stage sometimes referred to as “taking the training wheels off” to allow the model to fly autonomously, requires data sets that are derived from real-world circumstances. It is ready to go live if the model produces accurate and, more crucially, predicted outcomes using test data. If there are any issues with the model, it will go back to the training process until it reaches or surpasses the performance benchmarks.
Although going live is a major accomplishment, training the model does not cease at that point. Each data set that is analyzed by the AI might be seen as a new “lesson” that helps to enhance and refine the algorithm, depending on the model. When dealing with unexpected outlier data, data scientists must constantly check the model’s performance and outcomes. If, in very rare instances, the model produces incorrect findings, it may need to be fine-tuned so that it does not contaminate subsequent output.
Types of AI Model Training Methods
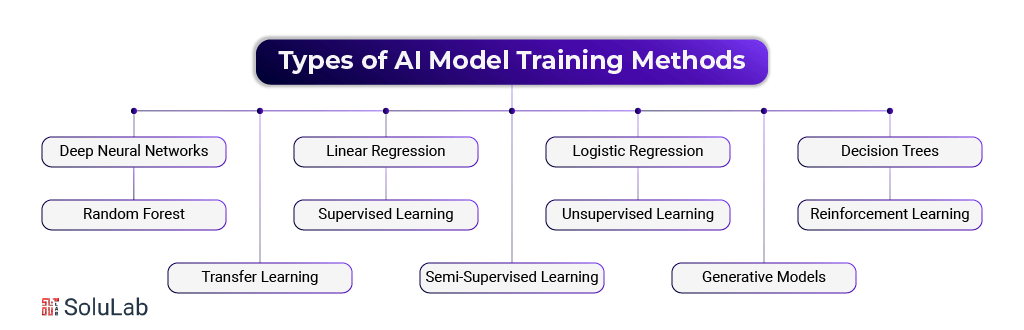
There is a wide variety of AI training methods, each with its own unique set of assumptions, outputs, capacities, and processing power requirements. In certain instances, a technique may overutilize resources, while in others, it may provide a yes/no answer (like a loan approval) when a more nuanced answer is required, like a conditional “no” until more paperwork is submitted. Data science teams risk squandering time and money if they go ahead without prior preparation while developing an AI model, thus it’s important to consider both objectives and available resources when making this decision.
-
Deep Neural Networks
Deep neural networks can manage complicated judgments based on different data linkages, in contrast to other AI models that rely on rules and inputs. Using a multi-layered architecture, deep neural networks may learn to anticipate outcomes or draw valid conclusions by spotting patterns and weighted correlations among data sets. Voice assistants like Alexa and Siri from Apple and Amazon are examples of deep neural networks in action.
-
Linear Regression
If you want to know how one variable affects another, you may use linear regression in statistics. If you want to simplify it for algebra, you may write it as y = Ax + B. A data set including input, output, and potential variable coefficients is used by this model to generate that formula. The output and input are assumed to be linear in the final prediction model. Making a sales prediction using historical sales data is one usage of linear regression.
-
Logistic Regression
Logistic regression, which originates in statistics, is a powerful model for cases with just one possible outcome. A common S-curve equation for probability calculations, the logistic function is the basis of logistic regression. To make predictions or decisions, such as whether a loan application should be authorized, logistic regression is used in AI modeling. It evaluates the likelihood and offers a binary answer. A financial application that uses logistic regression for fraud detection is one example of a use case.
-
Decision Trees
Decision trees are not new, even outside of artificial intelligence. Decision trees are functionally equivalent to flowchart nodes. Machine learning training procedures feed the tree with iterative data to determine when to add nodes and where to transmit their various pathways. The approval of a loan is one scenario in which decision trees are useful.
-
Random Forest
If Decision Trees build too much depth, they risk becoming overfit for their training sets. To make up for that, the random forest method takes a weighted average of the outcomes of the biggest agreement from a set of decision trees (hence the name “forest”) and uses it. Predicting consumer behavior using several decision trees covering various aspects of a customer’s profile is one use case for a random forest.
-
Supervised Learning
Having children follow a predetermined curriculum with structured lessons is what supervised learning is all about in the world of child education. Data scientists play the role of the archetypal teacher in artificial intelligence modeling by selecting training data sets, executing test data sets, and giving model feedback based on pre-established criteria. Locating aberrant cells in X-rays of the lungs is one use of supervised learning. Classifying X-rays as either abnormal or normal is part of the training data set.
-
Unsupervised Learning
Moving on with the child education example, unsupervised learning is a lot like the Montessori concept. It gives kids a lot of options and lets them explore them on their own accord, driven by their natural curiosity. In artificial intelligence (AI) modeling, this is feeding the system a dataset devoid of labels, parameters, and objectives, and then leaving it to its own devices to find patterns. One scenario where unsupervised learning might be useful is when a store wants to discover patterns in consumer behavior, so they enter quarterly sales data into an AI model.
-
Reinforcement Learning
You have engaged in reinforcement learning if you have ever used rewards to encourage a desired action. Experimental choices that result in positive or negative reinforcement are the foundation of reinforcement learning at the AI level. The AI eventually figures out how to handle a problem in the most effective way, meaning it learns from its mistakes and gets more positive reinforcement. The “you might also like” recommendations that YouTube displays to users based on their watching history is one use of reinforcement learning.
-
Transfer Learning
If given a new set of circumstances, an AI model may perform well. When an existing AI model is used as a foundation for a new model, this process is called transfer learning. Since it could be difficult to retrain a model that is very particular, this repurposing is most effective when applied to generic scenarios. A new artificial intelligence model for a particular kind of picture categorization using parameters from an existing model is one use case for transfer learning.
-
Semi-Supervised Learning
The first step of semi-supervised learning, which combines supervised and unsupervised learning techniques, is to train the model using a subset of labeled data sets. The program then refines patterns and generates new insights using unlabeled and uncurated data sources. As a rule, semi-supervised learning begins with training wheels—i.e., data sets that have labels attached to them. Unlabeled data becomes significantly dependent upon thereafter. One use of semi-supervised learning is in text classification models. These models are trained on a small selection of curated documents to determine their fundamental parameters, and then they are given massive amounts of unsupervised text documents.
-
Generative Models
One kind of unsupervised artificial intelligence, generative models generate new output by analyzing massive example datasets. This includes AI-generated pictures that draw on an image archive’s metadata as well as predictive text that uses a database of written texts. Instead of just categorizing data, generative models may learn from thousands—if not millions—of examples to provide unique answers. Chatbots like ChatGPT are generative models in action.
The Role of Data in AI Model Training
To be successfully trained, an AI model requires a large amount of data. of reality, data is the most important component of AI model training. Without it, the model does not learn. If the data is lacked quality, the model will learn incorrect things. Thus, data scientists carefully choose data sets for their tasks.
Data set curation must include the following aspects for successful AI model training:
- Quality of Data Sources: If an AI model receives a vast volume of unvetted, homogenous, and low-quality data, the outcomes will be bad. What constitutes “good data” differs based on the model at hand. When degrees of inaccuracy become unacceptable, it may be feasible to reverse the AI’s training process. However, it is fairly unusual for data scientists to restart a project from the beginning when inadequate data taints the model.
- Volume of Data: Practice makes perfect for training AI models. While a single data set may be a useful starting point, the training process necessitates a vast number of data as well as a sufficient level of variety and granularity in order to refine the model, improve accuracy, and discover outlier data.
- Diversity of Data: improved data set variety frequently results in improved accuracy in AI model training. Diverse experiences, like in the actual world, broaden skills and promote decision efficiency by allowing for a deeper understanding.
What to Look for in an AI Model Training Platform?
You can speed up the process of developing and training AI models using a range of AI model training tools. Some examples of these resources include gradient boosting, prebuilt model libraries, open-source AI model training frameworks, and tools to help with both coding and the environment. Some are model-specific, while others have strict requirements for available computing power.
Gather information by answering the following questions to help you choose the tool (or tools) that are most suited to your project:
- In the end, what are you hoping to achieve with your AI model?
- Please tell me your basic computing resources.
- Please tell me the whole AI model training cost and the extent of your project.
- In what stage of development are you currently?
- How well-rounded is your team?
- Is your project or sector subject to any regulations on governance or compliance?
- Which parts of your project are the most in need of assistance?
Based on your responses, you may compile a list of useful resources to supplement the training of your AI model.

The Bottom Line
A revolutionary step for organizations looking to automate processes, analyze data, and get predictive insights is training AI models. To achieve optimum performance, every stage of training an AI model is critical, from choosing the correct dataset to fine-tuning the models for accuracy. Recent developments in cloud computing and deep learning have made AI models more accessible, efficient, and scalable than in the past.
Our mission at SoluLab is to bring new frontiers in artificial intelligence. By incorporating photos, documents, texts, and APIs into AI processes, our newest project, InfuseNet, reimagines data empowerment. With the help of innovative algorithms such as GPT-4, FLAN, and GPT-NeoX, InfuseNet guarantees first-rate data security while improving decision-making, releasing important insights, and increasing operational efficiency. The goal of this platform is to facilitate massive expansion by transforming the way top AI development companies engage with and make use of their data.
Are you ready to level up your AI initiatives? Partner together with SoluLab and take advantage of our knowledge in training and developing AI models. Our staff is here to help you with any task, whether it’s improving current models or creating new solutions driven by AI. Contact us now and hire AI developers from SoluLab to transform your company with the most advanced AI technologies.
FAQs
1. How long does it take to train an AI model?
The time required for AI model training depends on multiple factors, including dataset size, model complexity, and hardware resources. Simple models can be trained in a few hours, while large-scale deep-learning models may take days or even weeks. Using cloud-based AI model training techniques, such as distributed training and transfer learning, can significantly reduce training time. It’s important to balance speed with accuracy to achieve the best results.
2. What is the most common AI model?
The most commonly used AI models vary based on the application. For natural language processing (NLP) tasks, transformer-based models like GPT-4 and BERT dominate, while convolutional neural networks (CNNs) are widely used for computer vision. In business applications, decision trees and random forests are frequently implemented for predictive analytics. Understanding types of AI model training methods helps businesses select the right model for their specific needs.
3. How does AI model training work?
AI model training involves feeding a model with labeled data, adjusting parameters through algorithms like backpropagation, and optimizing performance using loss functions. This differs from AI model training vs inference, where training is about learning from data, and inference focuses on making predictions with a trained model. Popular AI model training techniques include supervised, unsupervised, and reinforcement learning, each suited for different tasks.
4. What are the key challenges in AI model training?
AI model training presents several challenges, including data quality issues, model overfitting, and high computational costs. Choosing the right types of AI model training methods and ensuring diverse, well-labeled datasets can mitigate these challenges. Additionally, businesses must consider ethical AI practices and data privacy regulations when training models.
5. Can pre-trained models reduce AI training time?
Yes, leveraging pre-trained models can significantly reduce AI training time and computational requirements. Techniques like transfer learning allow businesses to fine-tune existing models with smaller datasets rather than training from scratch. This approach is widely used in NLP and computer vision, where models like GPT-4, FLAN, and GPT-NeoX provide a strong foundation for various AI-driven applications.


