AI embeddings can provide better training data, improving the data quality and reducing the need for manual labeling. Businesses may use AI technology to increase performance, streamline procedures, and change workflows by translating input data into formats that are readable by machines.
The way we live and work might be completely changed by the amazing instrument that is machine learning. However, the caliber of the training data utilized to create a machine-learning model has a major impact on the model’s performance. It’s often accepted that high-quality training data is the most important component of producing accurate and trustworthy machine learning outcomes.
In this blog post, we will go over the value of high-quality training data and how embedding in machine learning can improve it. But first, let’s get to know about what are embeddings in machine learning in more depth!
What is an Embedding in Machine Learning?
Machine learning (ML) is a specialized method of writing programs that process raw data and transform it into meaningful information for specific applications. Instead of defining rules manually, ML algorithms automatically learn patterns from data, allowing for more advanced analysis and prediction.
For instance, an ML system might be developed to detect machinery failures based on sensor data in an embedded system or recognize spoken commands from raw audio input to activate smart devices in a home. Unlike conventional software, where developers explicitly define rules, machine learning in embedded systems enables the system to learn these rules autonomously during the training process.
Traditional programming involves a developer designing a specific algorithm that processes input and applies pre-defined rules to deliver an output. This works well for straightforward problems, such as predicting water boiling at 100°C at sea level. However, in more complex situations, like identifying potential machine breakdowns, understanding the interplay of various factors like temperature and vibration levels becomes challenging.
In ML programs, engineers gather significant amounts of training data and feed it into algorithms designed to identify patterns. Through this process, the system automatically learns the rules needed for prediction. This capability is particularly valuable in embedded systems, where embeddings in machine learning can map complex relationships between data points to predict outcomes without manual rule-setting.
The resulting model, built through this training phase, is then used to infer predictions when new data is input. This process, referred to as embeddings mapping, is vital for optimizing the accuracy of the predictions generated by machine learning in embedded systems.
The Significance of High-Quality Training Data
The significance of high-quality training data in machine learning is that it directly influences the precision and dependability of machine learning models. For a model to effectively identify patterns and make accurate predictions, it must be trained on vast amounts of diverse, accurate, and unbiased data. If the training data is of poor quality or contains errors and biases, the model will deliver less precise and potentially biased results.
This emphasis on data quality extends to all types of AI models, including Foundation Models such as ChatGPT and Google’s BERT. A detailed analysis by The Washington Post examined the enormous datasets used to train some of the most powerful large language models (LLMs). Specifically, the study reviewed Google’s C4 dataset, emphasizing that both the quantity and quality of data are crucial, especially when training LLMs. This is where vector embeddings play a key role, helping to transform large datasets into a format that machine learning models can effectively process.
For instance, in image recognition tasks, if the training data contains images with incorrect or incomplete labels, the model may fail to accurately recognize or classify similar images during predictions. This issue can be mitigated by using an embedding layer, which helps the model better understand and categorize complex inputs such as images, text, or other data types.
Additionally, if the training data is biased toward certain groups or demographics, the model can learn and perpetuate these biases, resulting in unfair or discriminatory outcomes. For example, embedding examples from biased data can reinforce prejudiced behavior in models. A notable instance occurred when Google’s Vision AI model produced racist results due to bias in its training data. This highlights the importance of carefully curating and validating the datasets used to build machine learning models.
Related: Comparison of Large Language Models
What is Vector Embedding in Machine Learning?
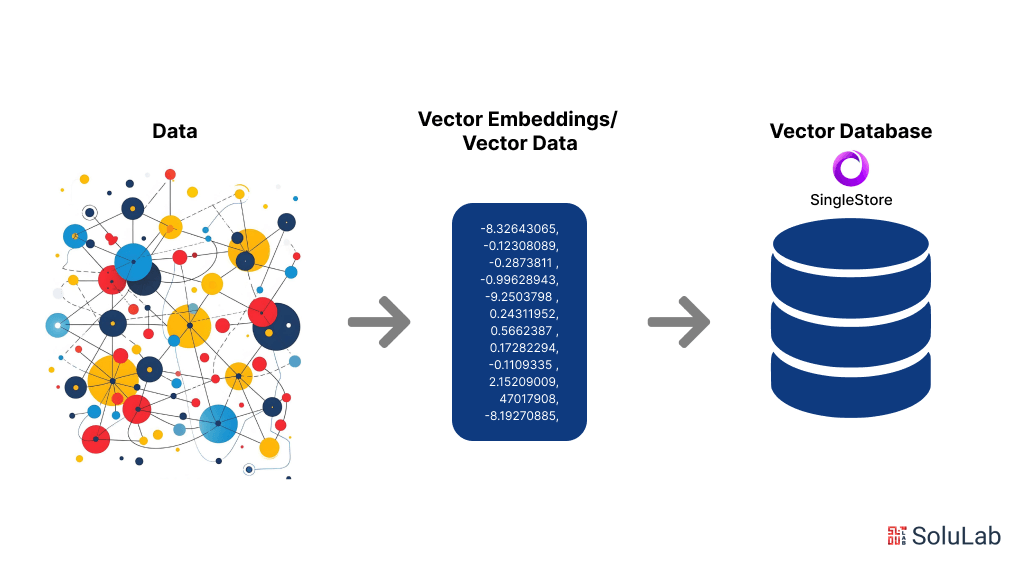
Vector embeddings are a fundamental concept in machine learning, particularly in the fields of natural language processing (NLP) and computer vision. They refer to the transformation of data, such as words or images, into numerical vectors that machine learning models can process. These vectors capture the semantic relationships and patterns in the data, allowing models to understand and make predictions more effectively.
An embedding model is designed to generate these vector representations by learning from large datasets. These models take raw input, such as words or sentences, and convert them into dense, lower-dimensional vectors. The goal is to map similar data points (e.g., words with related meanings) closer together in the vector space. This process helps improve the model’s ability to generalize and identify patterns across different inputs.
The embedding layer is an essential component in neural networks used to perform this transformation. It maps discrete data (like words or tokens) into continuous vectors, which the machine learning model can use for further processing. In natural language processing, this is particularly useful for tasks like text classification, machine translation, or sentiment analysis.
A specific use case of this concept is sentence embedding, where entire sentences are converted into vector representations. By representing sentences as vectors, models can perform more complex tasks such as sentence similarity analysis, text summarization, and semantic search. This helps machines grasp the context and meaning of sentences beyond just individual words.
In summary, vector embeddings, embedding models, the embedding layer, and sentence embedding are crucial elements in enabling machine learning models to handle and interpret complex data.
How Do Embeddings Work?
Embeddings are a key concept in machine learning and natural language processing (NLP), enabling the transformation of categorical or textual data into numerical formats that machine learning models can easily interpret. This process is essential for creating models that can understand relationships within the data, whether it’s words in a sentence or features of an object. Below is a detailed explanation of how embeddings work, categorized into specific sections:
What is Text Embedding in Machine Learning?
Text embedding in machine learning is a technique that converts text data into fixed-length vectors. These vectors, known as embeddings, capture the semantic meaning of the text. Each word or phrase is represented as a point in a multi-dimensional space, with similar words or phrases appearing closer together in this space. This is particularly helpful in understanding contextual relationships between words.
For example, the words “king” and “queen” may appear close together because they share similar contexts. Meanwhile, unrelated words like “banana” and “computer” would be far apart. What is text embedding in machine learning focuses on transforming raw text into vectors that machine learning models can process, making it possible for them to perform tasks like sentiment analysis, language translation, or text generation more effectively.

Embedding in NLP
Embedding in NLP (Natural Language Processing) is crucial for tasks that involve understanding and processing text. In NLP, embeddings translate words or entire sentences into numerical representations, allowing the model to learn the relationships between words and their meanings. Embeddings help the model comprehend the structure, meaning, and context of language.
For instance, in sentiment analysis, a model might use embeddings to analyze customer reviews. By converting the words in each review into vectors, the model can more easily classify whether the sentiment is positive, negative, or neutral. Similarly, embeddings in NLP are applied in tasks such as machine translation, question answering, and speech recognition. The embedding technique effectively captures linguistic features and relationships between words, which is a critical requirement for NLP tasks.
Feature Embedding in Machine Learning
Feature embedding in machine learning extends beyond NLP and can be applied to various types of input data, such as images, categorical data, and audio. The main idea behind feature embedding is to convert complex, high-dimensional input features into a low-dimensional space, where relationships between the features are preserved.
For example, in a recommendation system, a feature embedding might be used to represent both users and products as vectors in the same space. The closer the vectors are in that space, the more likely it is that a user would be interested in that product. This can greatly improve the efficiency and accuracy of machine learning models by reducing the dimensionality of the input data while still capturing essential relationships.
How Vector Embeddings Are Learned?
Vector embeddings are learned during the training process of a machine-learning model. They are initialized randomly or with pre-trained values and are updated based on the loss function during training. This means that the embeddings evolve over time to better represent the input data, helping the model make more accurate predictions.
In some cases, pre-trained embedding models like Word2Vec, GloVe, or BERT are used as a starting point. These pre-trained models have already learned robust embeddings from vast amounts of text data and can be fine-tuned on specific tasks. This enables machine learning models to leverage previously learned relationships and patterns in new datasets without starting from scratch.
The Role of the Embedding Layer in Neural Networks
The embedding layer is a crucial component of deep learning models, particularly in NLP applications. It is the layer that converts the input data (like words or tokens) into the corresponding embeddings. The embedding layer is often the first layer in an NLP model and transforms each word into a vector that is passed through the subsequent layers of the model.
For instance, in a neural network designed for text classification, the embedding layer would take in the raw text (such as sentences) and convert it into vectors. These vectors are then processed by other layers, such as convolutional or recurrent layers, to make a final prediction. This conversion helps the model interpret the input data more effectively, improving the model’s ability to learn complex relationships in the data.
Sentence Embedding for Contextual Understanding
While individual word embeddings are useful, sentence embedding takes it a step further by representing entire sentences or paragraphs as vectors. This allows the model to capture more complex relationships, such as the context in which words appear.
For example, in language translation tasks, a model using sentence embedding can understand the overall meaning of a sentence, not just individual word meanings. This enables more accurate translations that preserve the intent and tone of the original text. Sentence embedding models like BERT and GPT are widely used in modern NLP systems to generate high-quality embeddings that reflect the full context of the input.
By using vector embeddings, embedding models, and embedding layers, machine learning systems can efficiently process and learn from large, complex datasets. Whether applied to text, images, or other types of data, embeddings help reduce dimensionality, improve model performance, and ensure that the most important relationships in the data are captured effectively.
What Are Embedding Models?
Embedding models are algorithms designed to convert complex, high-dimensional data into more manageable and dense representations, known as embeddings, in a multi-dimensional space. These models help machine learning (ML) systems better understand and process intricate data patterns. By using embedding models, data scientists can empower ML systems to effectively interpret and draw inferences from such high-dimensional data. Below are several common types of embedding models used in machine learning applications.
1. Principal Component Analysis (PCA)
Principal Component Analysis (PCA) is a popular dimensionality-reduction technique that condenses complex datasets into lower-dimensional vectors. The model identifies patterns and similarities between data points, then compresses them into embedding vectors that maintain the essence of the original data. Although PCA improves the efficiency of data processing, it can lead to information loss during compression due to the reduction of dimensions. This method is widely used for visualizing and simplifying large datasets.
2. Singular Value Decomposition (SVD)
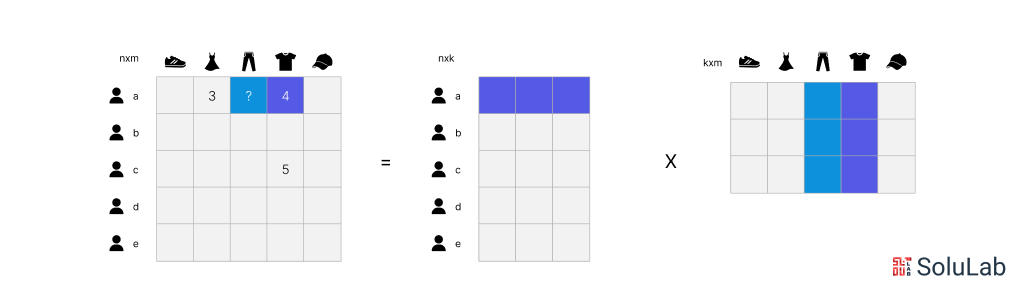
Singular Value Decomposition (SVD) is another embedding model that breaks down a matrix into its singular matrices. These singular matrices retain critical information from the original matrix, enabling ML models to better understand semantic relationships within the data. SVD is useful in various ML tasks such as image compression, text classification, and recommendation systems, helping models process data more efficiently by maintaining the most relevant features. Embeddings mapping in SVD allows the data to be represented in a form that simplifies these tasks.
3. Word2Vec
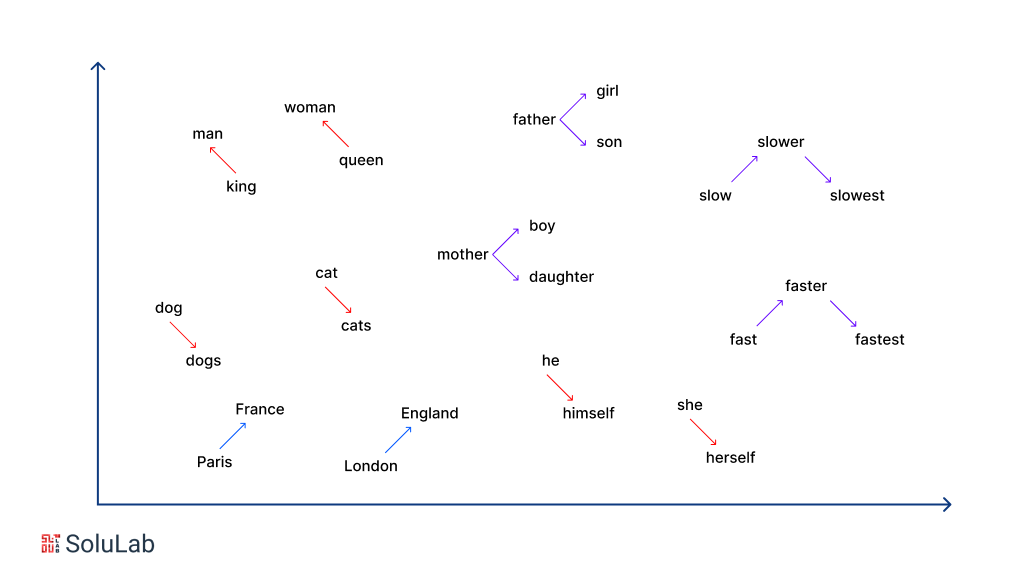
Word2Vec is a widely used algorithm designed to create word embeddings by associating words based on their contexts and semantic relationships. Data scientists train Word2Vec models using extensive textual datasets to enable natural language comprehension. This embedding model represents each word as a point in the embedding space, where words with similar meanings are placed closer together. There are two versions of Word2Vec: Continuous Bag of Words (CBOW) and Skip-gram. CBOW predicts a word from its surrounding context, while Skip-gram predicts the context from a given word. Despite its effectiveness, Word2Vec has limitations, such as difficulty distinguishing between words with multiple meanings in different contexts.
4. BERT
BERT (Bidirectional Encoder Representations from Transformers) is a transformer-based language model designed to understand languages in a manner similar to how humans do. Like Word2Vec, BERT creates word embeddings from the input data. However, BERT can also differentiate between the various contextual meanings of a word, even when the same word is used in different phrases. For instance, BERT can generate distinct embedding examples for the word “play” when used in the sentences “I went to a play” versus “I like to play.” This enhanced context-awareness makes BERT a powerful tool in tasks such as text classification, question answering, and language translation.
5. Knowledge Graph Embedding Model
A knowledge graph embedding model maps entities and relationships from knowledge graphs into low-dimensional vector spaces. This type of model allows ML systems to infer relationships between entities by analyzing how they are positioned relative to each other in the vector space. By creating these embeddings, ML models can reason with the rich and structured data in knowledge graphs, facilitating tasks such as recommendation, entity resolution, and semantic search. Embeddings mapping plays a crucial role in transforming the complex relationships of a knowledge graph into a form that ML models can process efficiently.
How to Create High-Quality Training Data Using Embeddings?
Creating high-quality training data is critical for building efficient and accurate machine-learning models. Feature embedding in machine learning is a powerful approach to transforming raw data into dense, informative representations, improving the learning process. Here’s how you can leverage machine learning embedding techniques to create high-quality training data:
1. Embedding Features for Better Data Representation
When working with large datasets, raw features often have high dimensions or may be sparse, which can limit model performance. By using feature embedding in machine learning, you can transform high-dimensional features into compact, dense vectors, or vector embeddings. These vectors capture the essential relationships between data points, enabling the machine-learning model to learn patterns more effectively. This is particularly useful when working with categorical variables or text data, which can be embedded into a meaningful continuous space.
2. Ensuring Consistent and Informative Data in Embedded Systems
For embedded systems, where computational and memory resources are often constrained, embedding techniques are essential for optimizing training data. By using machine learning embedding to reduce the dimensionality of the data, you ensure that the model can process high-quality training data while maintaining efficiency. Embedding not only makes the data more manageable but also ensures that important information is preserved, enabling better predictions in resource-constrained environments.
3. Utilizing Vector Embeddings for Text and Categorical Data
Embedding textual data, such as in natural language processing (NLP) tasks, is a common use case. Vector embeddings like Word2Vec or GloVe allow you to represent words or phrases as dense vectors in a continuous space, capturing the semantic relationships between them. When creating training data with these embeddings, it’s crucial to use a large, diverse dataset to ensure the vectors are informative and meaningful. This results in better language understanding by the model, leading to higher-quality outcomes for tasks like sentiment analysis, text classification, or machine translation.
4. Enhancing Data Consistency and Accuracy with Embeddings
Embeddings also help in reducing noise and improving data consistency. When transforming features into vector embeddings, similar data points are placed closer together in the embedding space, making it easier to detect and remove outliers or inconsistent entries. This process refines the quality of the training data, ensuring the model learns from accurate, relevant, and consistent information.
5. Cross-Domain Embedding for Versatile Training Data
When working across different domains or with multiple types of data, embeddings can unify the representations. For instance, combining visual data with textual descriptions can be achieved through joint machine learning embedding techniques, aligning different data types into the same vector space. This multi-modal approach enriches the training data, providing the model with diverse perspectives on the task, thereby improving its accuracy and performance.
In summary, leveraging feature embedding in machine learning and vector embeddings is essential for creating high-quality, structured, and informative training data. Whether working in an embedded system or large-scale AI models, embedding techniques enable models to better understand and learn from complex, high-dimensional data.
Best Practices for Embeddings in Computer Vision & Machine Learning
Embeddings play a critical role in enhancing AI and ML in data integration, especially in fields like computer vision and machine learning. When used effectively, embeddings can transform high-dimensional data into manageable and meaningful vector spaces, improving model performance and generalization. Below are some best practices for using embeddings in computer vision and machine learning:
1. Utilize Pretrained Models for Efficient Embedding
In computer vision tasks, using pre-trained models like ResNet or EfficientNet to extract embeddings can significantly speed up the training process. These models are already trained on vast datasets, allowing you to leverage their learned representations to create effective embeddings for your specific task. This is especially useful when integrating AI and ML in data integration, where you need to align and harmonize data from different sources or modalities.
2. Fine-Tune Embeddings for Domain-Specific Tasks
While pre-trained models provide a solid foundation, fine-tuning the embedding layers for domain-specific tasks can yield better results. For example, when building credit risk models with machine learning, fine-tuning embeddings on financial data or customer behavioral data can help capture nuances unique to that domain, leading to more accurate risk assessments.
3. Apply Dimensionality Reduction Techniques
In computer vision, the data is often high-dimensional, which can increase the computational load. Using dimensionality reduction techniques like PCA (Principal Component Analysis) or t-SNE helps to reduce the dimensionality of the embeddings while preserving important information. This can be particularly beneficial when implementing MLOps consulting services, where optimizing model performance and resource efficiency is crucial.
4. Regularize Embedding Layers to Prevent Overfitting
Embedding layers can have millions of parameters, which increases the risk of overfitting. To prevent this, apply regularization techniques such as L2 normalization or dropout to the embedding layers. This is especially important in machine learning models used for tasks like fraud detection or credit risk models with machine learning, where overfitting can lead to poor generalization and inaccurate predictions.
5. Evaluate Embeddings with Visualization Tools
To ensure the quality and usefulness of embeddings, employ visualization tools like t-SNE or UMAP to observe how data points are clustered in the embedding space. These tools help you validate whether the embeddings are effectively capturing patterns and similarities, crucial for projects involving MLOps consulting services, where understanding and optimizing model behavior is key to successful deployment.

6. Test Embeddings Across Different Models
Lastly, always test the embeddings with different machine-learning models to see which architecture works best. For instance, embeddings used in convolutional neural networks (CNNs) for image classification may behave differently when applied to transformer-based models. In projects focused on AI and ML in data integration, testing across multiple models can ensure that your embeddings are versatile and effective across various tasks.
By following these best practices, you can create more efficient and reliable models, improving performance in both computer vision tasks and broader machine learning applications like credit risk models with machine learning.
How SoluLab Can Help With Embedding in Machine Learning?
At SoluLab, as an AI development company, we specialize in providing the latest technology solutions for embedding in machine learning to help businesses enhance their AI models and data-driven strategies. Our team of experts ensures the creation of efficient and high-quality embedding models tailored to your specific needs, whether it’s for natural language processing (NLP), computer vision, or other AI-driven applications. With our deep understanding of vector spaces, feature embeddings, and dimensionality reduction, we deliver scalable solutions that allow your models to capture complex data patterns, ultimately improving performance and accuracy.
Our experience spans across industries, from finance to healthcare, integrating machine learning in embedded systems for faster, more reliable decision-making processes. Whether you’re looking to build embedding layers for your AI model or optimize your existing machine learning algorithms, SoluLab’s end-to-end support will ensure your business stays ahead in the competitive AI landscape. Ready to take your AI projects to the next level? Contact us today to discuss how we can help transform your machine-learning initiatives.
FAQs
1. What are embeddings in machine learning?
Embeddings in machine learning are a technique used to represent high-dimensional data in a lower-dimensional space. This approach allows machine learning models to process complex data types such as words, images, and other unstructured data more efficiently by capturing the semantic or contextual relationships between elements in the data. Embeddings enable models to make better predictions by recognizing patterns in the reduced feature space.
2. How does feature embedding improve machine learning models?
Feature embedding in machine learning improves model performance by reducing the dimensionality of input data while retaining its most important information. This helps models focus on key features without getting overwhelmed by noise or irrelevant data. By mapping complex data into a compact vector space, models can quickly identify patterns and similarities, leading to more accurate and efficient predictions, especially for tasks like image recognition and natural language processing.
3. What are vector embeddings used for in AI and machine learning?
Vector embeddings are widely used in AI and machine learning for tasks such as text analysis, recommendation systems, and image classification. They map high-dimensional input data like words or images into a continuous vector space where semantic or contextual relationships are preserved. This allows the model to better understand and process the data by finding similarities between items, which is crucial for tasks like sentiment analysis or product recommendations.
4. Why are embeddings important in machine learning for embedded systems?
Machine learning in embedded systems benefits greatly from the use of embeddings because they reduce the computational complexity of models, making them more suitable for devices with limited processing power and memory. By transforming high-dimensional data into lower-dimensional representations, embeddings enable machine learning algorithms to run efficiently on embedded devices, powering applications such as real-time image recognition, voice assistants, and predictive maintenance in IoT systems.
5. How can SoluLab help businesses with machine learning embeddings?
SoluLab offers tailored solutions for businesses looking to implement or optimize machine learning embeddings. Our team specializes in building efficient embedding layers that enhance model performance across various applications like NLP, image recognition, and recommendation engines. Whether you’re developing AI-driven products or optimizing existing systems, SoluLab can guide you through the entire process, from strategy to deployment.


